
数据结构与算法基础
线性表
基本数据结构
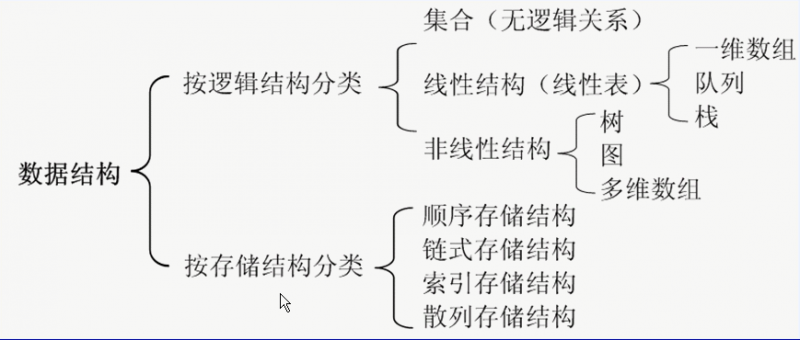
顺序表
在内存中是顺序存储的。内存划分出来的区域是连续的区块。

链表
在内存中是离散存储的。
head:头结点
结点:包括数据域和指针域(next 域)
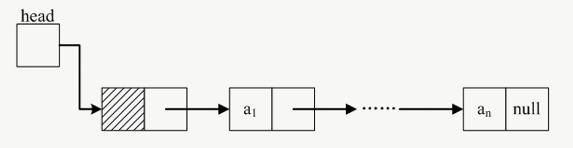
链表的分类
单链表
头结点 head 指向第一个结点的数据域,第一个结点的指针域指向下一个结点的数据域…
| 注意:单链表的最后一个结点的指针域为空(null)!!! |
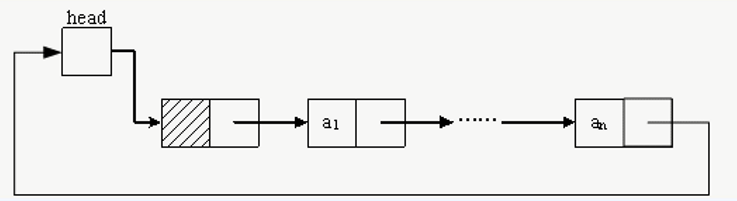
循环链表
| 注意:循环表的最后一个结点的指针域不为空,而是指向了头结点!!! |
双链表
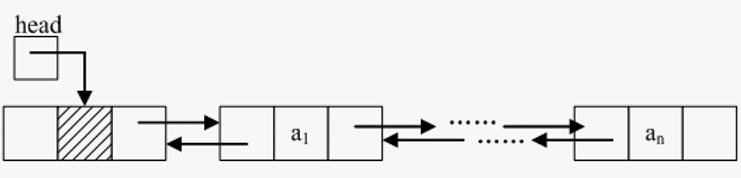
链表的操作
单链表的结点删除
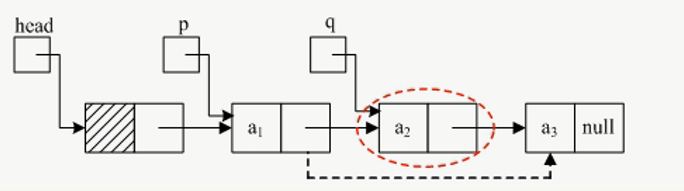
需求:删除 a2 结点
具体操作:将要删除的结点(a2)的前一个结点(a1)的 next 域指向 a2 的后一个的结点(a3)的数据域,然后释放(free)掉 a2 即可。
单链表的结点插入
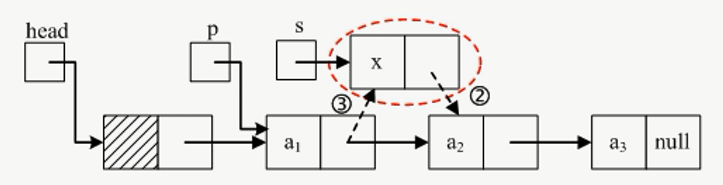
需求:在 a1 结点后面插入一个新的结点 x
具体操作:将 a1 的 next 域指向 x 的数据域,将 x 的 next 域指向 a2 的数据域即可。
顺序表与链表的比较
| 性能类别 | 具体项目 | 顺序存储 | 链式存储 |
|---|---|---|---|
| 空间性能 | 存储密度 | =1,更优 | < 1 |
| 容量分配 | 事先确定 | 动态改变,更优 | |
| 时间性能 | 查找运算 | O(n/2) | O(n/2) |
| 读运算 | O(1) | O([n+1]/2),最好情况为1,最坏情况为n | |
| 插入运算 | O(n/2)最好情况为0,最为情况为 n | O(1),更优 | |
| 删除运算 | O([n-1]/2) | O(1),更优 |
栈
- 思想:先进后出
队列
线性队列
- 思想:先进先出
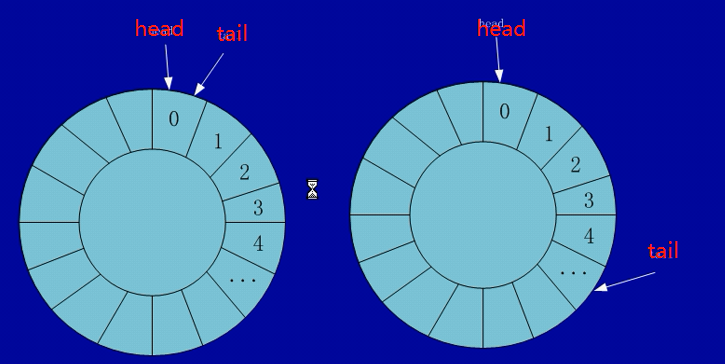
循环队列
head:头指针(队头)
tail:尾指针(队尾)
当队列中没有存入值的时候,head 指针和 tail 指针指向同一个元素,并且该元素的值是空的!!!
当循环队列开始存入值时,head 指针是不动的,tail 指针是后移一个位置。
| 注意: 循环队列中为了能够区别队空和队满,牺牲了队列的最后一个空间。 判空条件:head = tail 判满条件:head = tail+1 |
树和二叉树
树的一些基本概念
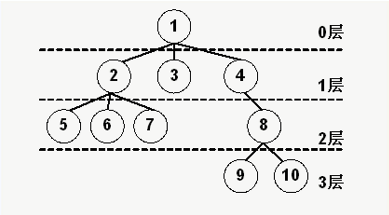
(结合下面的图进行解释)
- 结点的度:结点1与下一层的3个结点相关联,所以结点1的度为3。
- 树的度:所有结点度当中,度数最高的一个,所以如图树的度为3。
- 叶子结点:度为 0 的结点。
- 分支结点:除了叶子节点外,其它都属于分支结点。
- 内部结点:除了根节点和叶子结点外,其它都属于内部结点。
- 父结点
- 子结点
- 兄弟结点
- 层次:如图所示。
树的遍历
前序遍历
访问顺序:先访问根节点再访问子结点。
如上图的前序遍历为:1,2,5,6,7,3,4,8,9,10
后序遍历
访问顺序:先访问子结点再访问跟结点
如上图的后序遍历为:5,6,7,2,3,9,10,8,4,1
层次遍历
访问顺序:从上往下,一层一层访问
如上图的层次遍历为:1,2,3,4,5,6,7,8,9,10
二叉树
| 注意:二叉树并不是一种特殊的树,而是一种独立的数据结构,有明确的左结点和右结点。 |
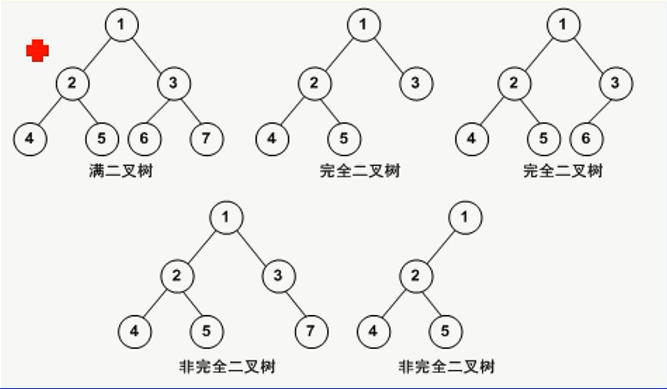
完全二叉树的概念:
若设二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第 h 层所有的结点都连续集中在最左边,这就是完全二叉树。
二叉树的重要特性:
在二叉树的第 i 层上最多有 2^(i-1) 个结点(i>=1)
深度为 k 的二叉树最多有 2^k - 1 个结点(k>=1)
对任何一颗二叉树,如果其叶子结点数为 n0,度为 2 的结点数为 n2,则 n0=n2+1
下图中的运算符号为向下取整。

二叉树的遍历
前序遍历
- 先访问根结点,接着访问左结点,最后访问右结点。
中序遍历
- 先访问左结点,接着访问根结点,最后访问右结点。
后序遍历
- 先访问左结点,结合访问右结点,最后访问根结点。
树与二叉树的转换
- 加线:在兄弟之间加一连线
- 抹线:对每个结点,除了其左孩子外,去除其与其余孩子之间的关系
- 旋转:以树的根结点为轴心,将整树顺时针转45°
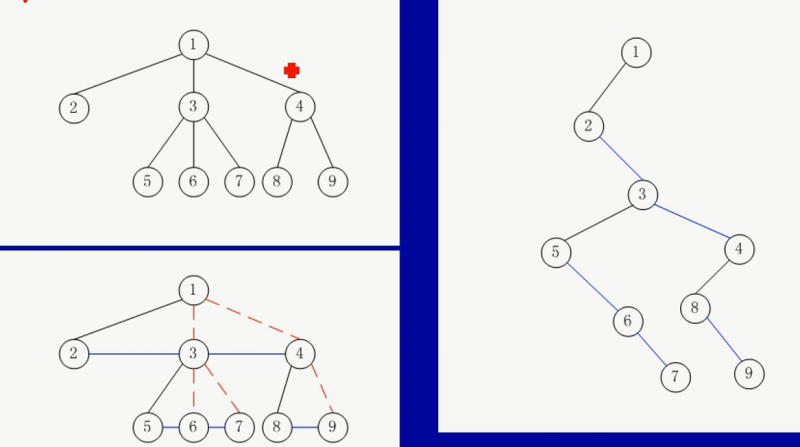
| 注意:转换后,树和二叉树的前序遍历一样。 |
二叉排序树
左子树的值小于根结点的值,右子树的值大于根结点的值。在常用的描述二叉排序树的存储结构中,关键字值最大的结点的右指针一定为空。
最优二叉树(哈弗曼树)
- 需要了解的基本概念
树的路径长度:从根结点到某结点的边数
权:人为赋值
带权路径长度:权值乘于边数
树的带权路径长度:所有的叶子结点的带权路径长度相加
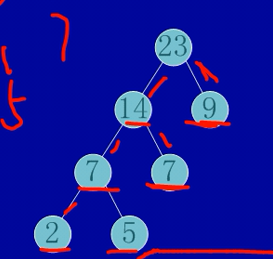
例子:由权值为9,2,5,7的4个叶子结点构造一棵哈弗曼树,该树的带权路径长度为(44)。
解析:
构造哈夫曼树的方法是依次从提供的权值中(9,2,5,7)选取两个权值最小(2,5)的最为左右结点,组合成一个新的根节点(2+5=7)也要参与到第二次权值选择中。也就是说,第二次要从(9,7,7)中选取两个最小的权值。
最后生成的树如下图:
例子:若一颗哈夫曼树共有9个顶点,则其叶子节点的个数为(5)。
n0 = n2 +1
9 = n0 + n2
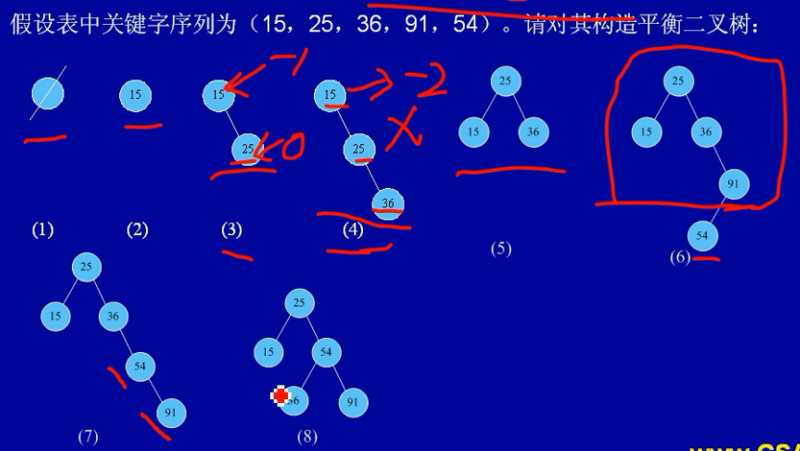
平衡二叉树
基本概念
它或者是一颗空数,或者是一颗这样的树:树中任一结点的左、右子树的深度相差不超过1(即平衡查找树的每个结点的平衡度只能为 -1,0,1 三个值之一)。
平衡树的建立
平衡树调整
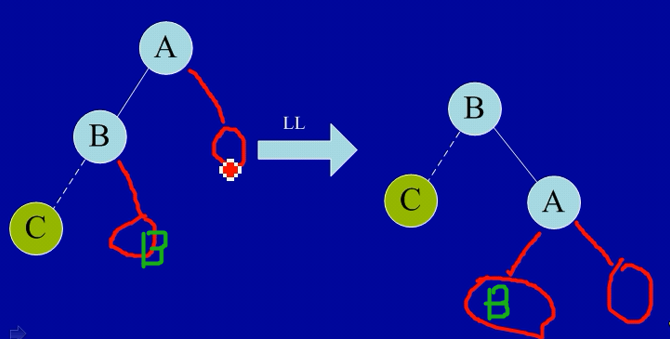
LL 型平衡旋转(单向右旋平衡处理)
- 第一种情况:

- 第二种情况
RR 型平衡旋转(单向左旋平衡处理)

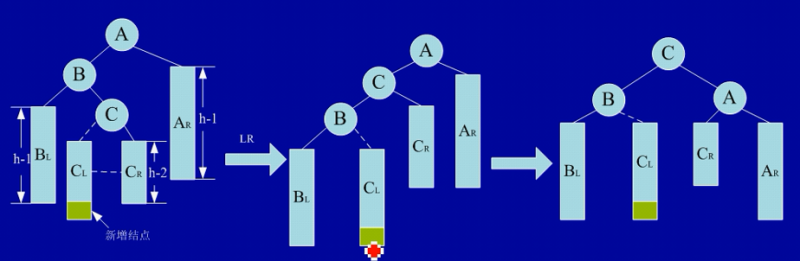
LR 型平衡旋转(双向旋转,先左后右)
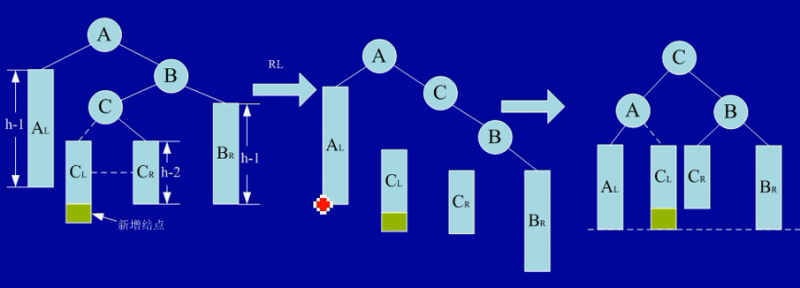
RL 型平衡旋转(双向旋转,先右后左)
图
图的构成
- 一个图是由两个集合:V和E组成,V是有限的非空顶点集合,E是用顶点对表示的边集合,图G的顶点集和边集分别记为V(G)和E(G),而将图G表示为G=(V,E),也就是说,决定一个图需要知道它的顶点集合与边的集合。
无向图与有向图
- 区别于边是否有箭头。
假设A,B为图中的两个顶点。
无向图的边表示方法:(A,B)
有向图的边表示方法:<A→B>、<B→A>
顶点的度(degree)
关联顶点的边数
- 有向图:入度和出度
子图
- 已知图A和图B,如果图B中所有的顶点都是图A中的顶点,图B中的所有边都是图A中的边,则图B是图A的子图。允许两种极端情况:什么都不删;删去所有点和所有线
完全图
无向图,每对顶点之间都有一条边相连,则称该图为完全图。
有向图,每对顶点之间都有两条有向边相互连接,则称该图为完全图。
路径和回路
- 假设图中的两个顶点A和B,A到B之间经过的边数称为路径。从顶点A出现,最后又回到顶点A,所走过的边组成的称为回路。
连通图和连通分量
无向图:任何两个顶点都有路径到达的图,称为连通图。
有向图:每两个顶点之间都能够有边(此处的边为有向边)到达的图,称为连通图。
连通分量:把连通图给分割出来,每一部分都是该图的连通分量。
邻接矩阵

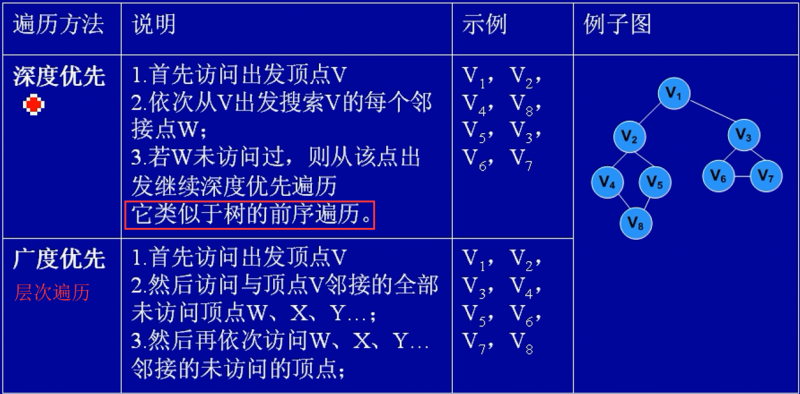
图的遍历
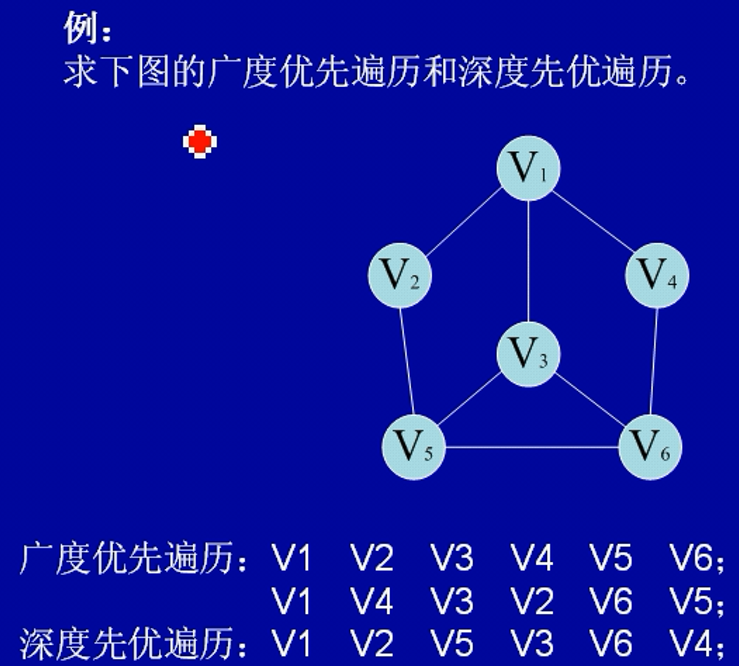
图的最小生成树
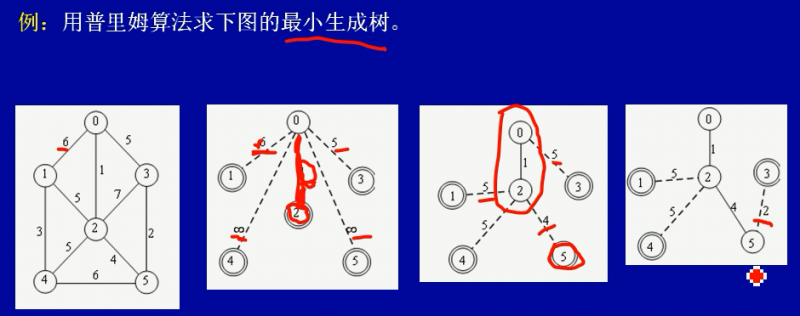
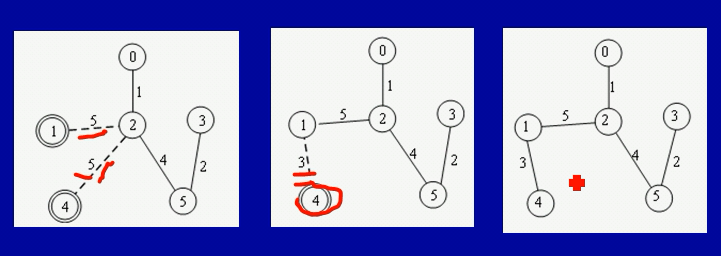
普里姆算法(Prim 算法)
先选取树的第一个顶点(如图点0),再判断所选点到其它点的权值,如果的所选点无法直接到达的点,权值暂时标记为无穷大,然后选取与点0的权值最小的点作为树的第二个顶点。然后再以第二个顶点为基点,判断与其它点的权值大小,循环以上得到第二个顶点的操作,直到生成了树。
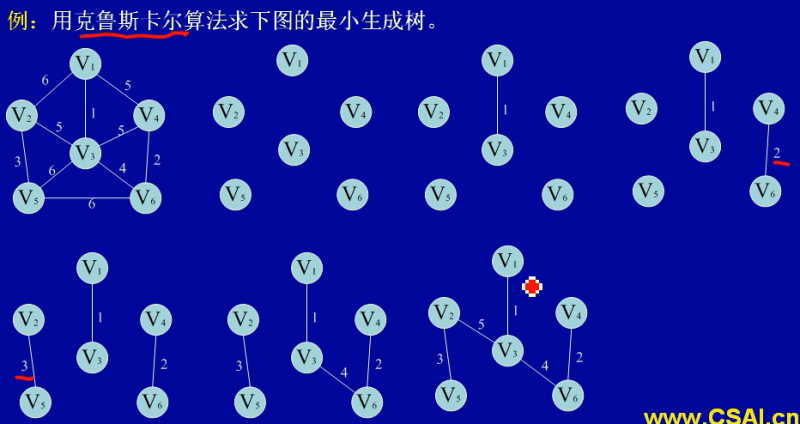
克鲁斯卡算法
- 算法思想:依次选取权值最小的边,只要不行成回路即可。
拓扑排序
AOV 网络
我们把用有向边表示活动之间开始的先后关系。
这种有向图称为用顶点表示活动网络,简称AOV网络。
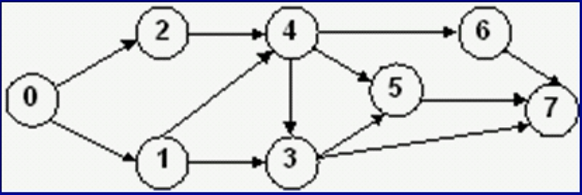
拓扑顺序
入度为0先进行。上图的拓扑序列有:02143567,01243657,02143657,01243567
关键路径
AOE 网络
在AOV网络中,如果边上的权表示完成该活动所需的时间,则称这样的AOV为AOE网络。
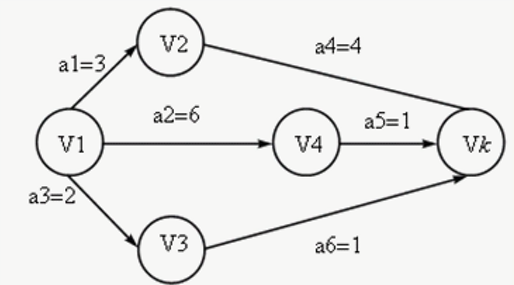
关键路径的几个重要概念
| 关键路径,就是从源点到终点,路径长度最长的路径。 |

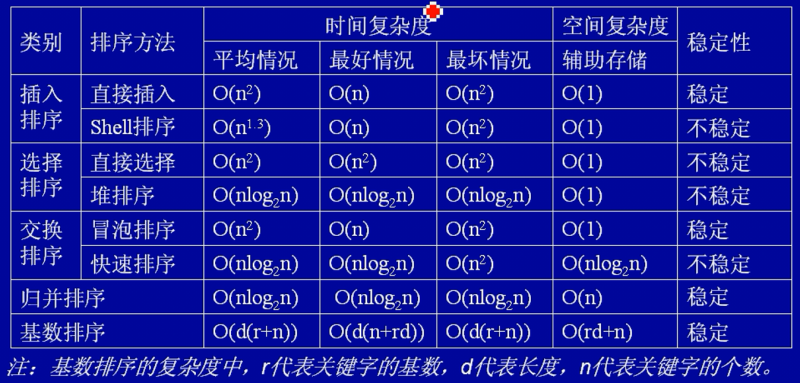
排序算法
各类排序算法时间复杂度和空间复杂度的对比表
哈希算法(Hash)
什么是 Hash 表
Hash 函数的构造方法
处理冲突方法
哈希表的查找
可以查考这个博客学习:https://www.cnblogs.com/zhangbing12304/p/7997980.html
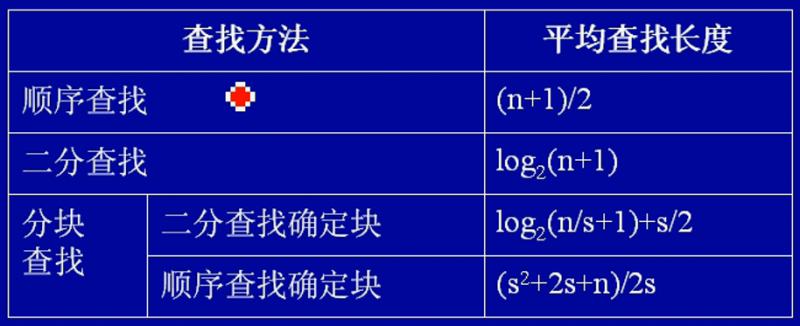
查找算法
编译原理
文法
终结符与非终结符
大写字母为非终结符
小写字母为终结符,不能单独在左边。
例子:
有文法G2[S]为:
- S->Ap
- S->Bq
- A->a
- A->cA
- B->b
- B->dB
则 S,A,B为非终结符,而p,q,a,b,c,d为终结符。
- VN 表示非终结符集合,即 VN = {S,A,B};
- VT 表示终结符集合,即 VT = {p,q,a,b,c,d};
- P 表示生成式,即上面给出的生成式(S->Ap等);
- S 表示开始符。
文法的类型
0 型文法
设G=(VN,VT,P,S),如果它的每个产生式α→β是这样一种结构:α∈( VN∪VT )且至少含有一个非终结符,而 β∈(VN∪VT),则G是一个0型文法。0型文法也称短语文法。
一个非常重要的理论结果是:0型文法的能力相当于图灵机(Turing)。或者说, 任何0型文语言都是递归可枚举的,反之,递归可枚举集必定是一个0型语言。
0型文法是这几类文法中,限制最少的一个,所以我们在试题中见到的,至少是0型文 法。
1 型文法
1型文法也叫上下文有关文法,此文法对应于线性有界自动机。它是在0型文法的基础上每一个α→β,都有 |β|>=|α|。这里的|β|表示的是β的长度。
例如:
A->B,|α| = 1,而 |β| = 1;
A->Bba,|α| = 1,而 |β| = 3.
| 注意:虽然要求|β|>=|α|,但有一特例:α→ε也满足1型文法。 如有 A->Ba 则 |β|=2,|α|=1符合1型文法要求。反之,如 aA->a,则不符合1型文法。 |
2 型文法
2型文法也叫上下文无关文法,它对应于下推自动机。2型文法是在1型文法的基础上,再满足:每一个 α→β 都有 α 是非终结符。如A->Ba,符合2型文法要求。
| 如 Ab->Bab 虽然符合1型文法要求,但不符合2型文法要求,因为其α=Ab,而Ab不是一个非终结符。 |
3 型文法
3型文法也叫正规文法,它对应于有限状态自动机。它是在2型文法的基础上满足:A→α|αB(右线性)或 A→α|Bα(左线性)。 α 代表的是非终结符,不一定要求字母相同。
| 特别注意:右线性和左线性,两套规则不能同时存在。 |
如有:A->a,A->aB, B->a, B->cB,则符合3型文法的要求。
但如果推导 为:A->ab, A->aB, B->a, B->cB
或推导 为:A->a, A->Ba, B->a, B->cB则不符合3型方法的要求了。
解释:
例子A->ab,A->aB,B->a,B->cB中的A->ab不符合3型文法的定义,如果把后面的ab,改成“一个非终结 符+一个终结符”的形式(即为aB)就对了。
例子A->a,A->Ba,B->a,B->cB中如果把B->cB改为 B->Bc的形式就对了,因为A→α|αB(右线性)和A→α|Bα(左线性)两套规则不能同时出现在一个语法中,只能完全满足其中的一个,才能算 3型文法。

正规式(正则表达式)
正规式与正规文法之间的转换:
*:代表的是大于等于0的数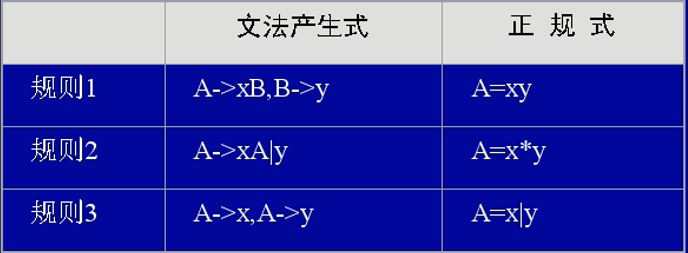


有限自动机(有穷自动机)
确定的有限自动机(DFA)

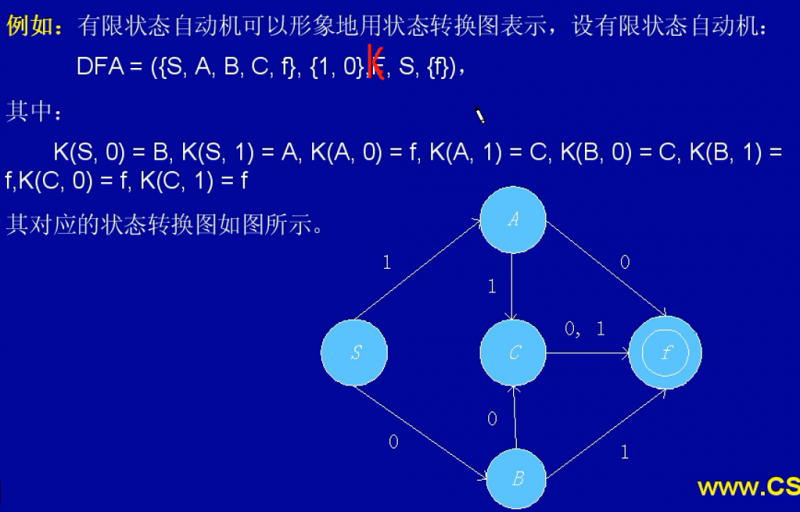
附加解释:
1.根据题目提供的状态集合 {S,A,B,C,f} 画出5个状态
2.终态集合中只有一个元素 f ,把 f 画成双圈表示终态
3.K(S,0)= B,表示在S状态,输入 0 就能到达B状态。
| 注意:DFA与NFA最大的区别就是,DFA只有一个确定的终态,NFA可以有多个终态。 |
不确定的有限自动机(NFA)

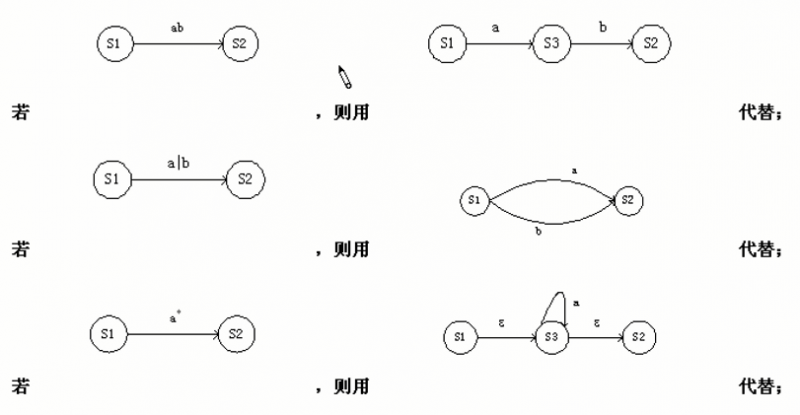
正规式与有限自动机之间的转换
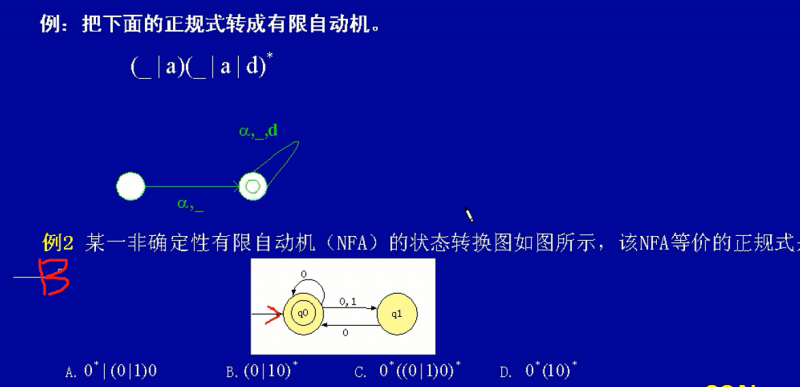
操作系统
进程
进程的三态图
就绪状态:进程已得到运行所需资源,只等待 CPU 的调度便可运行;
运行状态:进程已得到运行所需资源,并且得到了 CPU 的调度;
等待状态:不具备运行条件、等待时机的状态。(等待状态也称为阻塞状态)
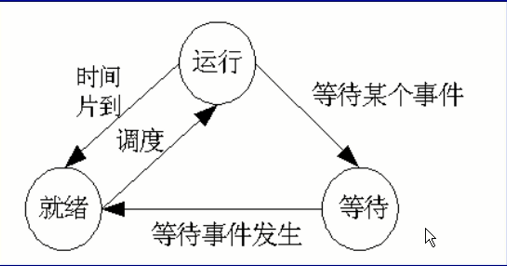
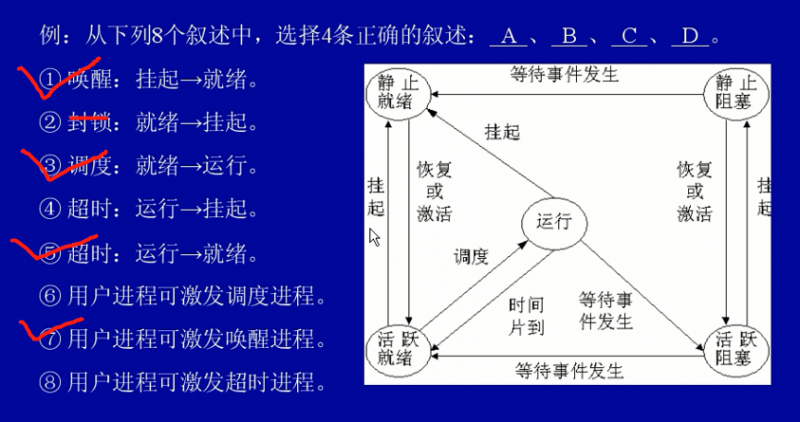
进程的五态图(了解)
进程的死锁
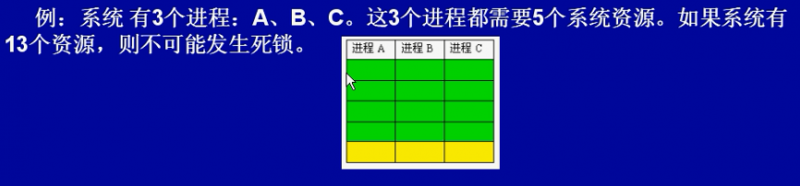
- 死锁发生的必要条件:
互斥条件:即一个资源每次只能被一个进程使用。
保持和等待条件:有一个进程已获得了一些资源,但因请求其他资源被阻塞时,对已获得的资源保持不放。
不剥夺条件:有些系统资源是不可剥夺的,当某个进程已获得这种资源后,系统不能强行收回,只能由进程使用完时自己释放。
环路等待条件:若干个进程形成环形链,每个都占用对方要申请的下一个资源。
- 解决死锁的策略:
死锁预防:例如:要求用户申请资源时一起申请所需的全部资源,这就破坏了保持和等待条件;将资源分层,得到上一层资源后,才能够申请下一层资源,它破坏了环路等待条件。预防通常会降低系统的效率。
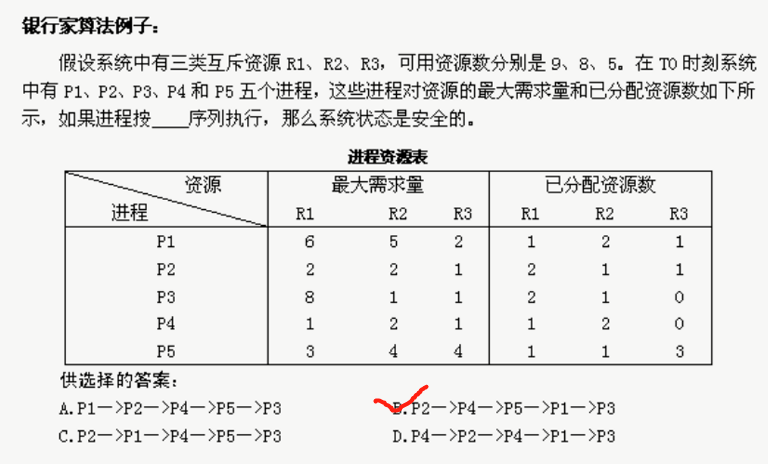
死锁避免:避免是指进程在每次申请资源时判断这些操作是否安全,典型算法是“银行家算法”。但这种算法会增加系统的开销。
死锁检测:前两者是事前措施,而死锁的检测则是判断系统是否处于死锁状态,如果是,则执行死锁解除策略。
死锁解除:这是与死锁检测结合使用的,它使用的方式就是剥夺。即将资源强行分配给别的进程。
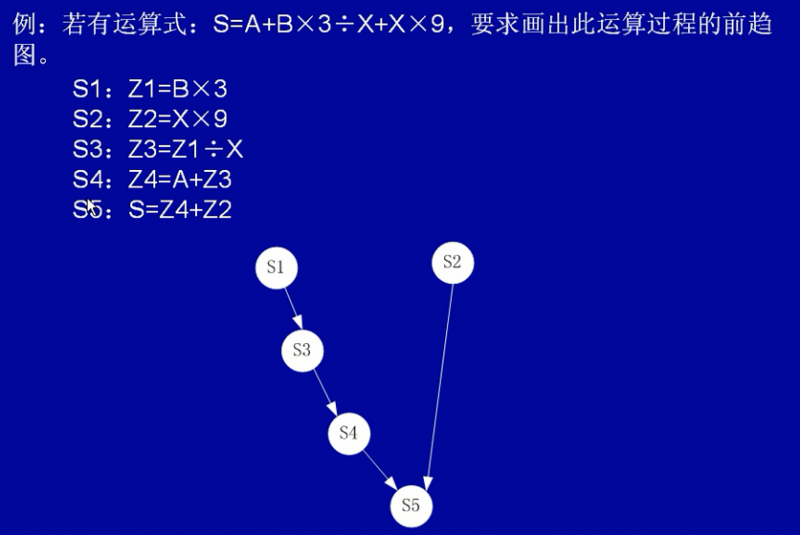
前趋图
前趋图是一个有向无循环图,记为 DAG ,用于描述进程之间执行的前后关系。图中的每个结点可用于描述一个程序段或进程,乃至一条语句;结点间的有向边则用于表示两个结点之间存在的偏序或前趋关系“→”。
如果 Pi 必须在 Pj 之前完成,可写成 Pi → Pj,称 Pi 是 Pj 的直接前驱,而 Pj 是 Pi 的直接后继。
把没有前驱的结点,称为初始结点。
把没有后继的结点,称为终止结点。
PV 操作
临界资源:诸进程间需要互斥方式对其进行共享的资源,如打印机、磁带机等。
临界区:每个进程中访问临界资源的那段代码称为临界区。
信号量:是一种特殊的变量。
P 操作:也称为 down()、wait()操作,使 S=S-1,若S<0,进程暂停执行,放入信号量的等待队列。
V 操作:也称为 up()、signal()操作,使 S=S+1,若S<=0,唤醒等待队列种的一个进程。
生产者与消费者问题
读者与写着问题
管程
概念:指关于共享资源的数据及在其上操作的一组过程或共享数据结构及其规定的所有操作。
PV操作缺点:
易读性差、不利于修改和维护、正确性难以保证
在利用管程方法来解决生产者-消费者问题时,首先便是为它们建立一个管程,并命名为PC。包括两个过程:
(1) put(item)过程。生产者利用该过程将自己生产的产品投放到缓冲池种,并用整型变量 count 来表示在缓冲池种已有的产量数目,当 count >= n 时,表示缓冲池已经满了,生产者须等待。
(2) get(item)过程。消费者利用该过程从缓冲池种取出一个产品,当 count <= 0 时,表示缓冲池中已无可取用的产品,消费者应等待。
存储
实存管理
存储管理的任务是存储空间的分配与回收。在现代操作系统中通常有的单一连续分配、固定分区分配、可变分区分配(动态分配法)三种分配方法。
虚存管理
页式存储组织
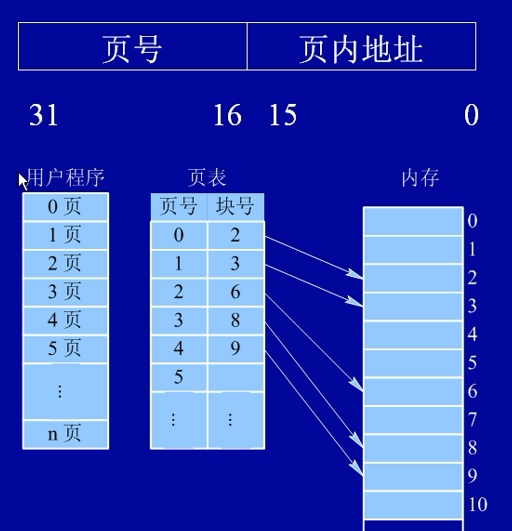
优点:利用率搞,产生的内存碎片小,内存间分配及管理简单。
缺点:要有相应的硬件支持,增加了系统开销;请求调页的算法如选择不当,有可能产生抖动现象。
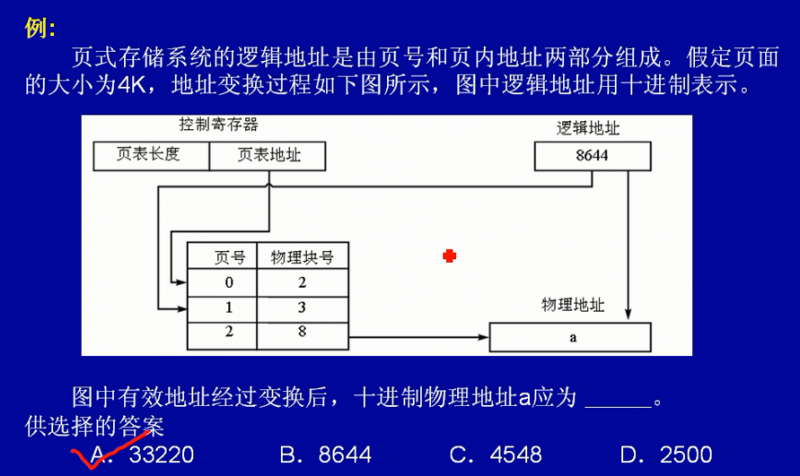
解析:
已知页面大小为 4K ,因为 4K = 2^12,所以页内地址有12位。将逻辑地址8644(10)转成二进制,10 0001 1100 0100(2),其中的低12位为页内偏移量,最高两位(10)则为页号,所以逻辑地址8644的页号为10(2),即十进制的2,所以从上图表格可以得到物理块号为8,即二进制的1000。把物理块号和页内偏移地址拼合得 1000 0001 1100 0100,化为十进制得33220。
段式存储组织
优点:便于多道程序共享内存,便于对存储器的保护,各段程序修改互不影响。
缺点:内存利用率低,内存碎片浪费大。
段页式存储组织
分段之后,在每段中进行分页。
优点:空间浪费小、存储共享容易、存储保护容易、能动态连接。
缺点:由于管理软件的增加,复杂性和开销也随之增加,需要的硬件以及占用的内容也有所增加,使得执行速度大大下降。
在段页式管理的存储器中,实存等分为页、程序按逻辑模块分成段。
在多道程序环境下,每道程序还需要一个基号作为用户标志号。
每道程序都有对应的一个段表和一组页表。一个逻辑地址包括基号x、段号s、页号p和页内地址d四个部分。
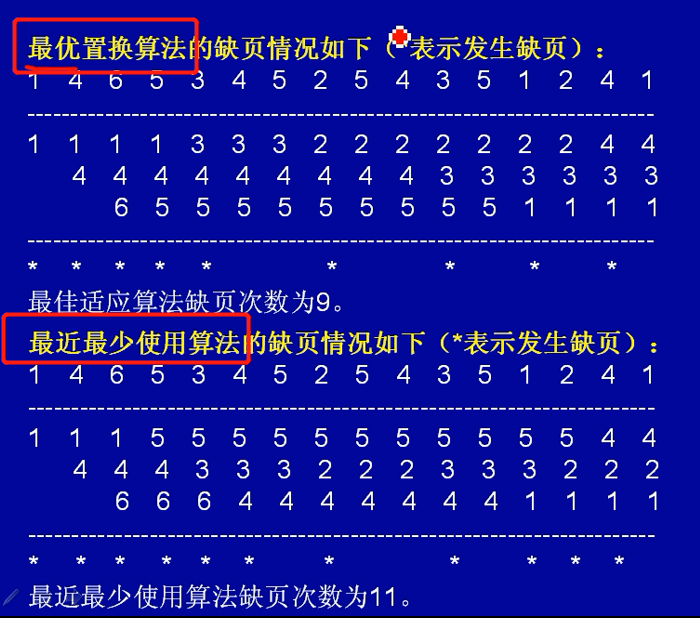
页面置换算法
最优算法(OPT)
先进先出算法(FIFO):保留最近需要使用的页面
最近最少使用算法(LRU):淘汰最长时间没有被访问的页面
没有进行页面置换的,不算入缺页次数,但刚刚开始的3次需要算入。

局部性原理
时间局部性:被引用过一次的存储器位置在未来会被多次引用(通常在循环中)。
空间局部性:如果一个存储器的位置被引用,那么将来他附近的位置也会被引用。
作业管理
作业右三部分构成,即程序、数据和作业说明书,它是用户在完成一项任务过程中要求计算机系统所做工作的集合。作业的状态有后备状态、运行状态和完成状态三种。
等待时间 = 开始时间 - 提交时间
周转时间 = 完成时间 - 提交时间
最短作业优先调度算法

优先数调度算法
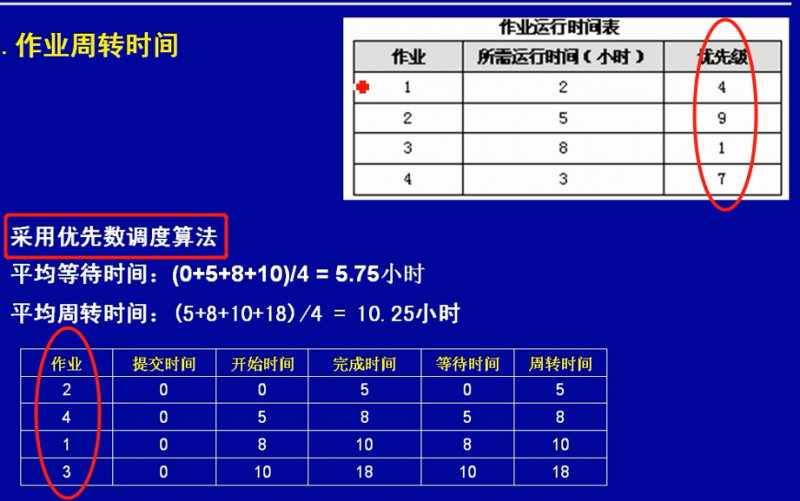
先来先服务调度算法
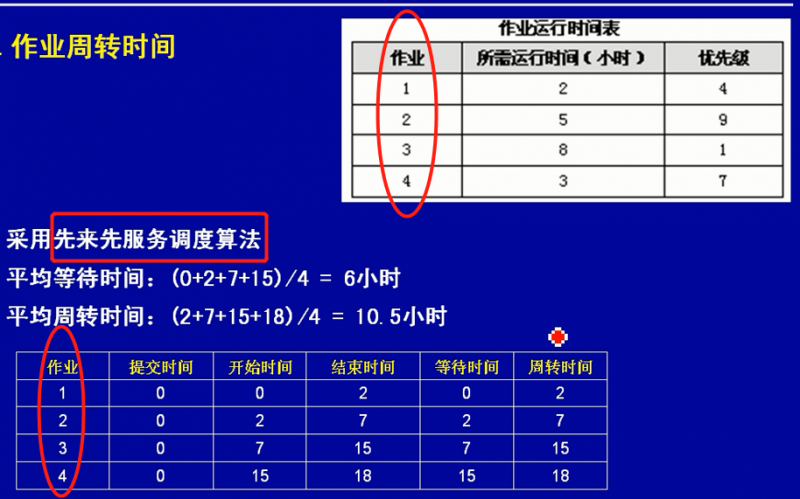
时间片轮转算法
每个任务轮流执行一个时间片,时间片结束时,不管任务是否完成都要先暂停任务。
带权作业周转时间
单个作业的带全周转时间:作业的周转时间 ➗ 作业的实际运行时间
作业平均带权周转时间:所有单个作业的带权周转时间相加 ➗ 作业个数
最高响应比有线算法
比较难,需自行查阅资料学习。
文件管理
文件目录
一级目录结构(不允许存在相同名字的文件)
二级目录结构(允许存在相同名字的文件)
树形目录结构(注意绝对路径和相对路径)
Spooling技术
举例:平时在打印店打印的时候,在打印机打印的过程中,多台电脑可以同时继续提交打印任务,这时打印机也不会说出什么问题,因为电脑提交的打印任务是放到了打印机的缓存区,然后打印机会根据提交的顺序打印。这就是利用到了 Spooling 技术。
系统开发与软件工程
软件开发生命周期模型
瀑布模型
瀑布模型是一种理想化的开发模型,瀑布模型要求有明确的需求分析,而要达到这一点在现实开发中几乎不可能。与其最相适应的软件开发方法是结构化方法。
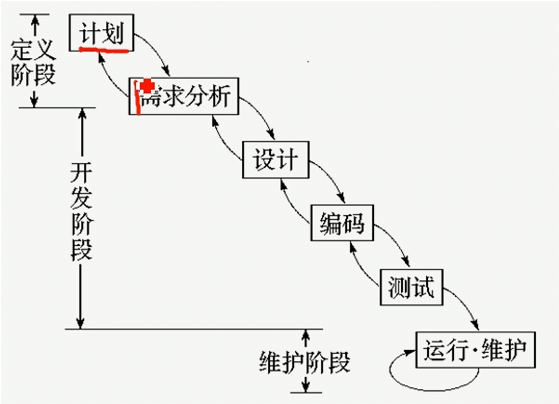
原型法
原型法的最大特点就是它采用了一种动态定义需求的方法。这样,优势也就提现出来了,即不需要有明确的需求。
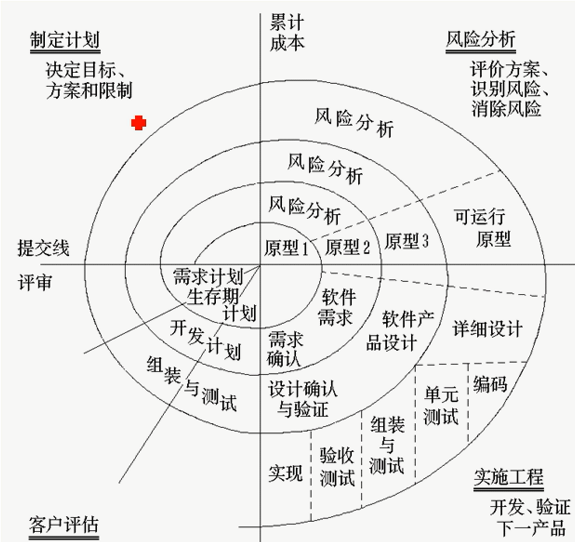
螺旋模型
螺旋模型结合了瀑布模型和演化模型的优点,最主要的特点在于加入了风险分析。它是由制定计划、风险分析、实施工程、客户评估这一循环组成的,它最初从概念项目开始第一个螺旋。
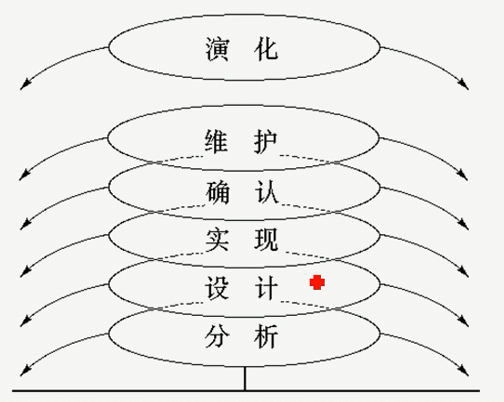
喷泉模型
喷泉模型主要用于描述面向对象的开发过程,最核心的特点是迭代(有重复部分)。所有的开发活动没有明显的边界,允许各种开发活动交叉进行。
项目管理基础
软件项目管理的内容
软件项目管理的核心问题(铁三角):成本、质量、进度
软件项目管理的主要活动:
- 启动软件项目
- 度量
- 估算
- 风险分析
- 进度安排
- 追踪和控制
软件项目管理的三个阶段:
- 项目启动阶段(项目立项、可行性分析、项目的初步计划)
- 项目实施阶段(制定计划、执行计划、监控进度、根据实际情况进行计划调整、关注需求变更)
- 项目关闭阶段
软件项目估算
自顶向下估算法
优点:耗费时间少
这种方式的一种通常采用的方法,但其并不能够有效地解决项目估算的问题,经常容易使得估算值与实际值产生很大的差异。比较适合估算系统级别的。
自底向上估算法
这种方式通常能够得到较为客观的、可操作的估算结果,而且还能够使得项目组成员主动地参与,并且通常能够对自己所做的承诺权利守信,从而为项目树立了一个良好的文化。
软件规模估算
LOC 估算法
也就是估算软件的代码行数,通常使用 KLOC(千行代码)为单位
FP 估算法
FP(功能点)是一种衡量工作量大小的单位,它的计算方法是:功能点 = 信息处理规模 X 技术复杂度,其中,技术复杂度 = 0.65 + 调节因子
- 信息处理规模
- 技术复杂度(取值0~0.05之间)
软件工作量估算
- IBM 模型
- 普特南模型
- COCOMO 模型
软件成本估算
常用的估算辅助方法
Delphi 法,专家判定技术
Standard-component 方法
软件项目组织与计划
- 项目计划包括:项目组计划和个人项目计划
- 计划的编制,应该包括两个重要的图标:人员职责矩阵和甘特图
- 已获值分析(EVA) 是最常用的项目进度监控方法。
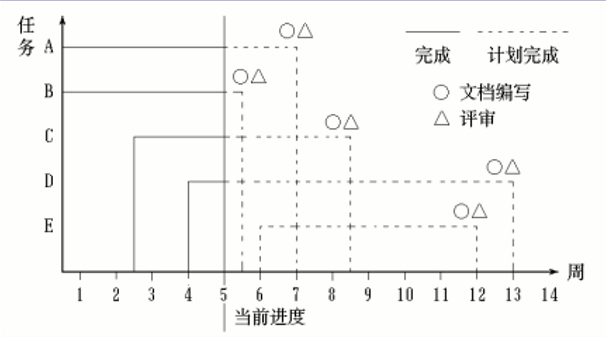
Gannt 图
特点:
- 使用水平线段表示任务的工作阶段
- 线段的起点和终点分别对应着任务的开工时间和完成时间
- 线段的长度表示完成任务所需的时间
优点:
- 标明了各任务的计划进度和当前进度,能动态地反映项目进展
缺点:
- 难以反映多个任务之间存在的复杂逻辑关系
PERT 技术和 CPM 方法
PERT 技术叫做计划评审技术,CPM 方法叫做关键路径法。
它们都是安排开发进度,指定软件开发计划的常用的方法。它们都采用网络图来描述一个项目的任务网络,也就是从一个项目的开始到结束,把应当完成的任务用图或表的形势表示出来。
配置管理
软件配置管理的任务包括:
- 制定配置管理计划
- 实施变更管理
- 实施版本管理
- 发行管理
实现变更管理需要借助于配置数据库和基线。
配置数据库可以分为:开发哭、受控库、产品库。
基线:是指软件生命周期各开发阶段末尾的特定点,也称为里程碑。
版本管理:是指对系统不同版本进行标识和跟踪的过程。
风险管理
风险管理通常包括三个主要活动:
风险识别
风险估计
风险驾驭
软件测试与维护
数据库
ER 模型
基本概念
实体(Entity):是指客观存在可以相互区别的事物。实体可以是具体的对象,如:一辆汽车等;也可以是抽象的事件,如:一次借书等。实体型用矩形表示。
属性(Attribute):实体有很多特性,每一个特性称为属性。每个属性有一个值域,其类型可以是整数型、实数型、字符串型。属性用椭圆形表示。
联系(Relationship):
1:1联系:如果实体集 E1 中的每个实体最多只能和实体集 E2 中的一个实体有联系,反之亦然,那么实体集 E1 对 E2 的联系称为“一对一联系”。
1:N联系:如果实体集 E1 中的每个实体与实体集 E2 中任意个(零个或多个)实体有联系,而 E2 中每个实体至多和 E1 中的一个实体有联系,那么实体集 E1 对 E2 的联系称为“一对多联系”。
M:N联系:如果实体集 E1 中的每个实体与实体集 E2 中任意个(零个或多个)实体有联系,反之亦然,那么实体集 E1 对 E2 的联系称为“多对多联系”。
ER 模型转换成关系模式的规则
一个实体型转换为一个关系模式,实体的属性就是关系的属性,实体的码就是关系的码。
一个1:1联系可以转换为一个独立的关系模式,也可以与任意一端对应的关系模式合并。 如果转换为一个独立的关系模式,则与该联系相连的各实体的码以及联系本身的属性均转换为关系的属性, 每个实体的码均是该关系的候选码。 如果与某一端实体对应的关系模式合并,则需要在该关系模式的属性中加入另一个关系模式的码和联系本身的属性。
一个1:n联系可以转换为一个独立的关系模式,也可以与n端对应的关系模式合并。 如果转换为一个独立的关系模式,则与该联系相连的各实体的码以及联系体本身的属性均转换为关系的属性,而关系的码为n端实体的码。
一个m:n联系转换为一个关系模式。 与该联系相连的各实体的码以及联系本身的属性均转换为关系的属性,而关系的码为各实体码的组合。
三个或三个以上实体间的以上多元联系可以转换为一个关系模式。 与该多元联系相连的各实体的码以及联系本身的属性均转换为关系的属性。 而关系的码为各实体码的组合。
键(码)、函数依赖及范式
概念理解
超键:在关系模式中,能唯一标识元组的属性集称为超键。
候选键:在关系模式中,能唯一标示元组并且不含多余属性的属性集成为候选键。值得注意的是,超键与候选键是有区别的,超键可能含有多余属性,而候选键不能。
主键:在一个关系的若干个候选键中随意指定一个作为关键字,则此关键字就是主键。
外键:如果关系模式R1中的某属性集不是R1的候选键,而是关系模式R2的候选键,则这个属性集对模式R1而言是外键。注意,这不是对于R2而言的。
主属性:候选码中的诸属性称为主属性。
例题:
请指出关系模式: 成绩(学号,姓名,课程号,成绩)的主属性和非主属性注:学生无同名.
候选键:(学号,课程号)、(姓名,课程号)
主属性:学号,姓名,课程号
函数依赖
函数依赖:设R(U)是属性集U上的关系模式,X,Y是U的子集 若对于R(U)的任意一个可能的关系r,r中不可能存在两个元组在X上的属性值相等, 而在Y上的属性值不等,则称X函数确定Y或Y函数依赖于X,记作X→Y。
三个基本定义:

范式
第一范式(1NF):在关系模式 R 中,当且仅当所有域只包含原子值,即每个分量都是不可再分的数据项,则称实体 E 是第一范式。
第二范式(2NF):当且仅当实体 E 是第一范式,且每一个非键属性完全依赖主键时,则称实体 E 是第二范式。(存在数据冗余等问题,可以每个非键属性给单独拆分到一个关系模式里)
第三范式(3NF):当且仅当实体 E 是第二范式,且 E 中没有非主属性传递依赖于码时,则称实体 E 是第三范式。(消除传递函数依赖)
无损联接分解
有损:不能还原
无损:可以还原
无损联接分解:所谓无损联接分解是指将一个关系模式分解成若干个关系模式后,通过自然联接和投影等运算仍能还原到原来的关系模式,则称这种分解为无损联接分解。

关系代数及元组演算
关系代数的基本运算
关系代数的五种基本运算并、差、笛卡尔积、选择和投影。
并(Union,用符号U表示)
计算两个表在集合理论上的联合。 给出表R和S(两者有相同元/列数),RUS的联合就是所有在R里面有,或S里面有,或在两个表里面都有的记录集合。
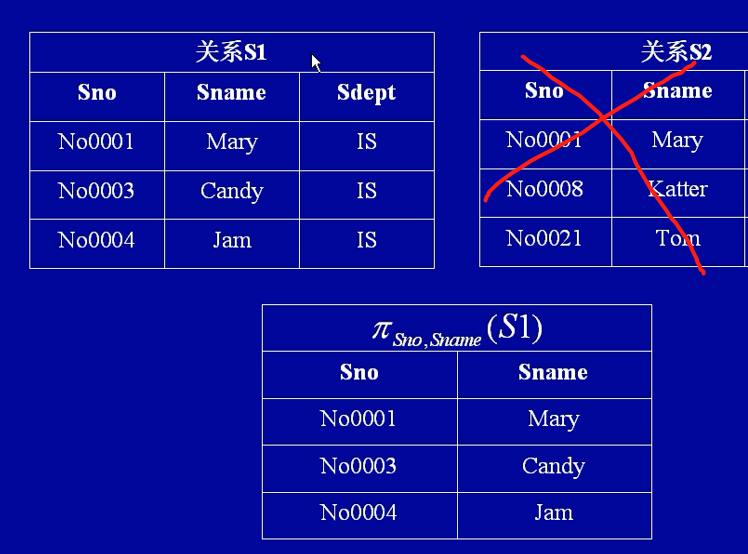
差(Difference,用符号-表示)
计算两个表的区别的集合。 令R和S是拥有相同元/列的表。 R-S是在R里面却不在S里面的记录的集合。
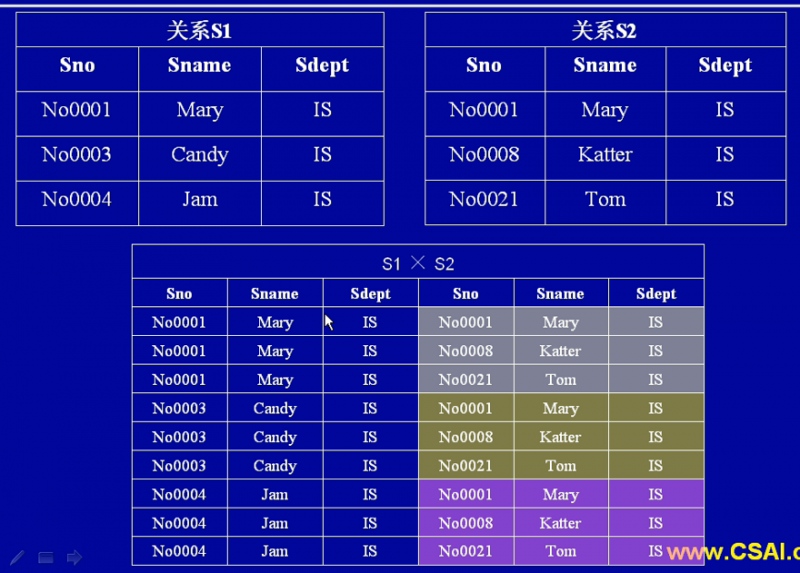
笛卡尔积(PRODUCT,用符号x表示)
计算两个关系的笛卡尔乘积。令R为有K1元的表,令S为有K2元的表。RxS是所有k1+K2元记录的集合,其前k1个元素来自R里的一条记录,而后K2个元素来自S里的一条记录。(可以简单理解为字段的拼接)
投影(Project,用符号π表示)
从一个关系里面抽取指明的属性(列)。 令R为一个包含一个属性X的关系。 πX(R)= { t(X) | t ∈ R },这里t(X)表示记录里的属性X的值。
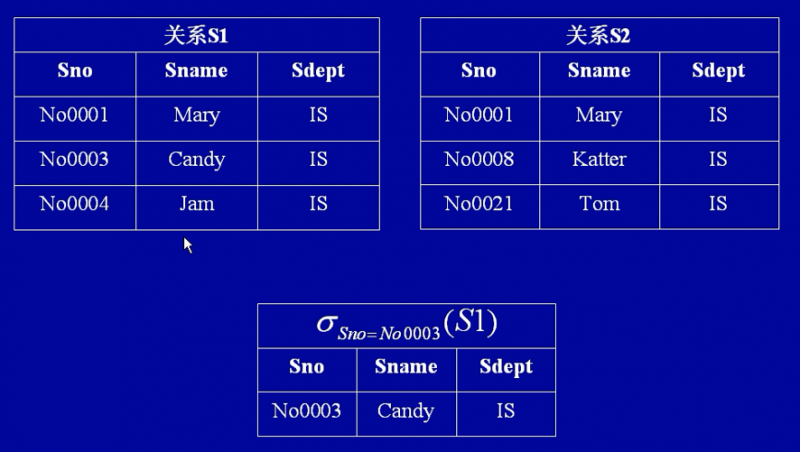
选择(Select,用符号 σ 表示)
从关系里面抽取出满足给定限制条件的记录。
令R为一个表,包含一个属性A。 σ A= a(R) ={ t ∈ R| t(A) = a }这里表示R的一条记录,而 t(A)表示记录 t 的属性A的值。
交(Intersection,用符号∩表示)
计算两个表集合理论上的交集。给出表R和S,R∩S是同时在R和S里面的记录的集合。我们同样要求R和S拥有相同的元/列数。
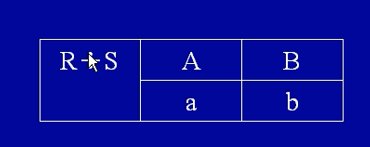
联接(Join,用符号⋈表示)
通过共同属性联接两个表。令R为一个有属性A,B,C的表,令S为一个有属性C,D,E的表。两个表有一个共同的属性C。

除(Division,用符号➗表示)
设有关系R(X,Y)与关系S(Z),其中,X,Y,Z为属性集合。假设Y和Z具有相同的属性个数,且对应属性出自相同域。关系R(X,Y)➗S(Z)所得的商关系是关系R在属性X上投影的一个子集,该子集和S(Z)的笛卡尔积必须包含在R(X,Y)中,记为R➗S。
元组演算
SQL语言
SQL是结构化查询语言。
SQL的基本功能:
1.数据定义(Data Definition):可以简便地建立数据库和表的结构。
2.数据管理(Data Management):可以实现表中数据的输入,修改、删除和更新。
3.数据查询(Data Query):可以对数据库中的内容进行查询。
SQL的特点:
1.SQL语言简洁,易学易用。 完成核心操作只需要9个动词。
2.有十分灵活和强大的查询功能。用一条SQL命令就能完成相当复杂的查询操作。
3.功能丰富。SQL虽然名为查询语言,但实际上具有数据定义、数据查询、更新和数据控制等多种功能。
4.SQL是一种高度非过程化的语言。用户只需要指出”做什么”,而不需指明”怎么做”。
基本表的创建
例:建立一个”学生”表Student,由学号Sno,姓名Sname性别Ssex,年龄Sage、所在系Sdept五个属性组成。 其中学号不能为空,值是唯一的,并且姓名取值也唯一。
1 | CREATE TABLE Student |
1 | /*使用CREATE语句创建学生_课程表*/ |
基本表的修改
新增列
- 向 Student 表增加 “入学时间” 列,其数据类型为日期型。
1 | ALTER TABLE Student ADD Scome DATE; |
- 不论基本表中是否已有数据,新增加的列一律为空值。
修改数据类型
- 将年龄的数据类型改为短字长整数。
1 | ALTER TABLE Student MODIFY Sage SMALLINT; |
删除约束
- 删除学生姓名必须取唯一值的约束。
1 | ALTER TABLE Student DROP UNIQUE(Sname); |
基本表的撤销
删除表
1 | DROP TABLE STUDENT; |
基本表定义一旦被删除,表中的数据、在表上建立的索引和视图都将自动的被删除掉。
视图的创建
- 例:建立信息系学生的视图。
1 | CREATE VIEW S_Student |
本例中省略了视图 S_Student 的列名,由子查询中SELECT子句中的三个列名组成。
- 例:建立信息系学生的视图,并要求进行修改和插入操作时仍需保证该视图只有信息系的学生。
1 | CREATE VIEW S_Student |
视图不仅可以建立在一个基本表上,也可以建立在多个基本表上。
例:建立信息系选修1号课程的学生视图。
1 | CREATE VIEW S_S1 |
视图不仅可以建立在一个或多基本表上,也可以建立在一个或多个已定义好的视图上,或建立在基本表与视图上。
例:建立信息系选修1号课程且成绩在90分以上的学生视图。
1 | CREATE VIEW S_S2 |
视图的删除
删除语句的格式为:
DROP VIEW〈视图名〉
视图删除后视图的定义将从数据字典中删除,所以删除一个视图时要将由该视图导出的其它视图一一删除,否则用户使用时会出错。
索引的创建
建立索引有利于加快查询速度。用户可以根据应用环境的需要,在基本表上建立一个或多个索引,以提供多种存取路径,加快查找速度。
- 例:为学生-课程数据库中的 STUDENT、 COUSE、SC三个表建立索引。其中STUDENT表按学号升序建立唯一索引, COUSE表按课程号升序建立唯一索引,SC表按学号升序和课程号降序建立唯一索引。
1 | CREATE UNIQUE INDEX Stusno ON Student(Sno); |
索引的删除
1 | DROP INDEX <索引名> |
数据查询
比较常用的查询语句不特别列出。
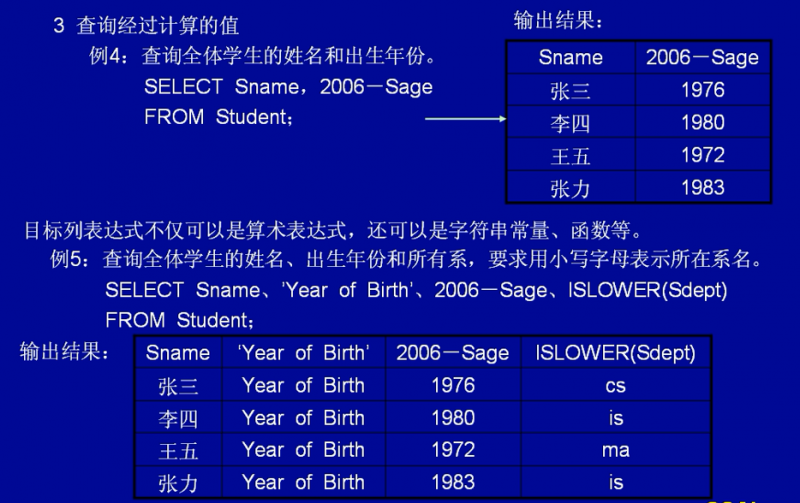
自定义输出列名
1 | SELECT Sname NAME、'Year of Birth' BIRTH、2006-Sage BIRTHDAY、 |
DISTINCT(distinct) 的作用:消除重复行
如果査询结果包含许多重复的行,要去掉重复行,必须指定 DISTINCT短语
1 | SELECT DISTINCT Sno |
确定范围
例:查询年龄在20~30岁包括20岁和30岁)之间的学生的姓名和年龄。
1 | SELECT Sname, Sage |
例:查询年龄不在20~30岁之间的学生姓名和年龄。
1 | SELECT Sname, Sage |
确定集合
1 | IN ('IS','SS','CS') |
字符匹配(LIKE)
%(百分号):代表任意长度(长度可为0)的字符串。例如,a%b表示以a开头,以b结尾的任意长度的字符串。
_(下横线):代表任意单个字符。例如,a_b代表以a开头,b结尾的长度为3的字符串。
- 如果用户要查询的字符串本身就含有%或,这时就可以使用 ESCAPE ‘<换码字符>’ 短语对通配符进行转义。
1 | ESCAPE '\' 短语表示 '\'为换码字符,这样匹配串中紧跟在\后面的字符"_"不再具有通配符的含义,转义为'_'字符。 |
例:查询DB_ Design课程的课程号和学分。
1 | SELECT Cno, Ccredit |
例:查询以”DR”开头,且倒数第3个字符为的课程的详细情况
1 | SELECT * |
涉及空值的查询
例:某些学生选修课程后没参加考试,所以有选课记录,没有成绩。查询缺少成绩的学生的学号和相应课程号。
1 | SELECT Sno, Cno |
- 这里的s不能用“=”号取代。
例:查询所有有成绩的学生学号和课程号。
1 | SELECT Sno, Cno |
对查询结果排序
| 用户可以用 ORDER BY子句对查询结果按照一个或多个属性列的升序(ASC)或降序(DESC)排列,缺省值为升序。 |
例:査询选修了3号课程的学生的学号及其成绩,査询结果按分数的降序排列。
1 | SELECT Sno, Grade |
对于空值按升序排列,含空值的元组将最后显示。若按降序排列,空值的元组将最先显示。
使用集函数
1 | COUNT() 统计元组个数 |
例:查询学生总人数。
1 | SELECT COUNT(*) |
例:査询选修了课程的学生总人数。
1 | SELECT COUNT(DISTINCT Sno) |
分组
GROUP BY子句将査询结果表按某一列或多列值分组,值相等的为一组。对查询结果分组的目的是为了细化集函数的作用对象。
例:求各个课程号及其相应的选课人数
1 | SELECT Cno, COUNT(Sno) |
该语句对查询结果按Cno值分组,所有具有相同Cno值的元组为一组,然后对每一组使用集函数 COUNT计算。
如果分组后还要按一定的条件对这些组进行筛选,最终只输出满足指定条件的组则可以用 HAVING短语指定筛选。
例:査询选修了3门以上课程的学生学号。
1 | SELECT Sno |
带有 ANY 或 ALL 谓词的子查询
子査询返回单值时可以用比较运算符,而使用ANY或ALL谓词时必须同时使用比较运算符。其一般格式为:
比较运算符ANY:表示在子査询中满足比较运算符的某个值。
比较运算符ALL:表示在子査询中满足比较运算符的所有值。
例:査询其它系中比信息系某一学生年龄小的学生姓名和年龄
1 | SELECT Sname, Sage |
计算机组成原理与系统结构
流水线
流水线概念
流水线是指在程序执行时多条指令重叠进行操作的一和准并行处理实现技术。各种部件同时处理是针对不同指令而言的,它们可同时为多条指令的不同部分进行工作,以提高各部件的利用率和指令的平均执行速度。
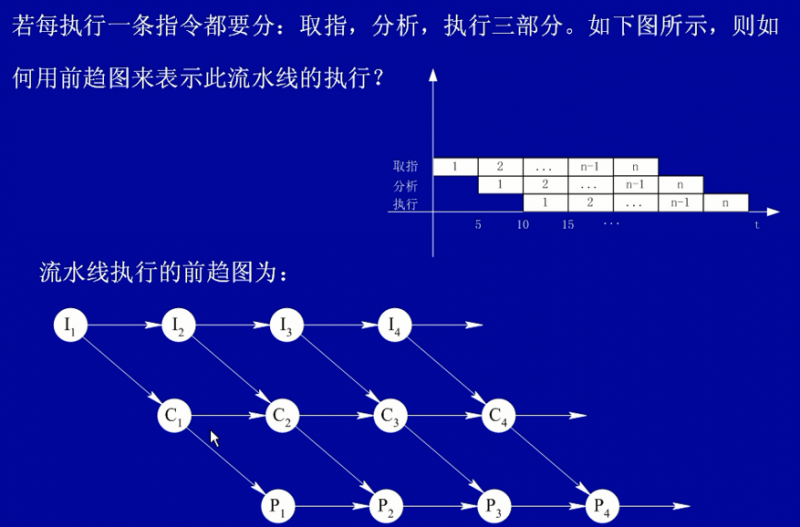
流水线指令运行时间的计算

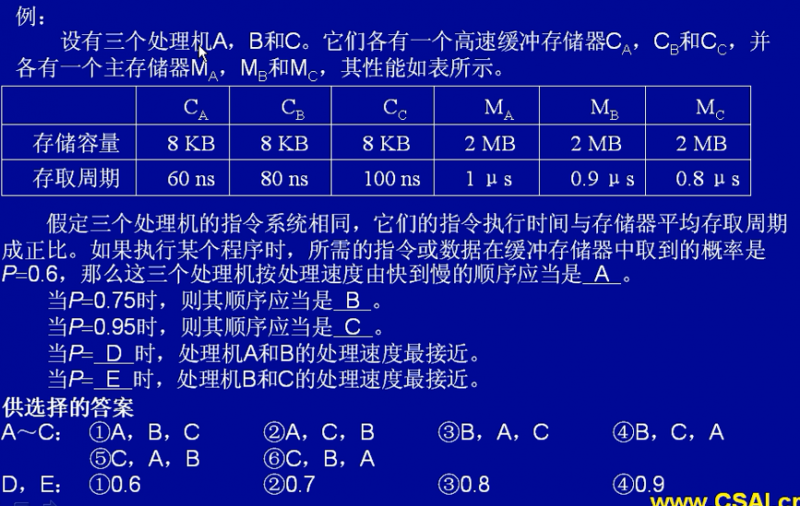
例:若指令流水线把一条指令分为取指、分析和执行三部分,且三部分的时间分别是 t(取指)=2ns,t(分析)=2ns,t(执行)=1ns,则100条指令全部执行完毕需()ns。
计算:(2+2+1)+(100-1)x2=5+198=203
注意:如果考试中,按公式计算选不出答案,得换一种方式算,即以运行时间最长的为基准,把每部分的时间都看成一样的来运算。
流水线的吞吐率
指在单位时间内流水线所完成的任务数量或输出的结果数量。
公式:指令总条数/总时间,如上例题计算吞吐率:100/203
流水线的加速比
完成同样一批任务,不使用流水线所用的时间与使用流水线所用的时间之比称为流水线的加速比。
可能产生的最大加速比为4。
流水线的效率
效率 = 吞吐量x △t
效率 = 加速比/k,k为流水线分的级别
高速缓冲存储器
Cache的概念
CPU内部对通用寄存器的存取操作是速度最快的,不是 Cache。
★ Cache的功能:提高CPU数据输入输出的速率,调和CPU速度与内存存取速度之间巨大的差异。
★在计算机的存储系统体系中, Cache是访问速度最快的层次。
★使用 Cache改善系统性能的依据是程序的局部性原理。
命中率
如果以 h 代表对 Cache的访问命中率,t1 表示 Cache的周期时间,t2 表示主存储器周期时间,以读操作为例,使用“ Cache+主存储器”的系统的平均周期为 t3 ,则
$$
t3=h×t1+(1-h)×t2
$$
其中,(1-h)又称为失效率(未命中率)。
求出系统的平均周期越短的速度越快。
下面的真题,A~C 选项实际上就是要求出系统的平均周期再进行比较(P为命中率)。
而D,E选项,要求最接近,即 A的平均周期-B的平均周期 的绝对值最小,因此我们可以直接令 A的平均周期-B的平均周期=0 进行计算。
Cache 的读写过程
★写直达:当要写 Cache时,数据同时写回主存储器,有时也称为写通。
★写回:CPU修改 Cache 的某一行后,相应的数据并不立即写人主存储器单元。而是当该行被从 Cache 中淘汰时,才把数据写回到主存储器中。
★标记法:对 Cache 中的每一个数据设置一个有效位。
地址映像
★常见的映像方法有直接映像、相联映像和组相联映像。
★地址映像是将主存与 Cache的存储空间划分为若干大小相同的页(或称为块)。例如某机的主存容量为1GB,划分为2048页,每页512KB; Cache容量为8MB,划分为16页,每页512KB。
直接映像(分区)
全相联映像(分组)(块冲突概率低,Cache 空间利用率高)
组相联映像(先分区再分组)
内存编址方法
1个字节 = 8位
1字 = 64位或32位(具体看计算机系统是哪一种)
编址
3位地址能够有8个空间。(2^3 = 8)
芯片的拼接
16*4位的芯片(空间数X数据位),即地址线为4(2^4=16),数据线为4。
存储相关计算问题
计磁数 = (外半径 - 内半径) X 道密度 X 记录面数
注意:硬盘的第一面与最后一面是保护用的,要减掉。如4个双面的盘片的记录面数是4x2-2=6。
非格式化容量位密度ⅹ最内圈直径ⅹ总磁道数
注意:位密度是每道不同的,但每道的容量是相同的。0道是最外面的磁道,其位密度最小。
格式化容量每道扇区数ⅹ扇区容量总磁道数
平均数据传输速率每道扇区数ⅹ扇区容量ⅹ盘片转数
存取时间寻道时间等待时间
注意:寻道时间是指磁头移动到磁道所需的时间;等待时间为等待读写的扇区转到磁头下方所用的时间。

数制
进制转换
十进制转其他进制:短除法
其他进制转十进制:如(111)2转十进制,为1 X 2^2 + 1 X 2^1 + 1X2^0 = 7(10)
定点整数:原码
将最高位用做符号位(0表示正数,1表示负数),其余各位代表数值本身的绝对值的表示形式。

例如:
X = +0110,则 [X]原 = 0 0110;
X = -0110,则 [X]原 = 1 0110;
定点小数:原码
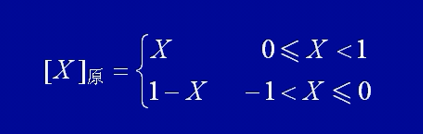
定点小数的小数点是固定在最高位和次高位之间,定点整数的小数点是固定在最低位后面。
例如:
X = +0.1011,则 [X]原 = 0 1011;
X = -0.1011,则 [X]原 = 1 1011;
定点整数:反码

正数的反码与原码相同。负数的反码符号位为1,其余各位为该数绝对值的原码按位取反。这个取反的过程使得这种编码称为“反码”。
例如:
X = +0110,则 [X]原 = 0 0110;
X = -0110,则 [X]原 = 1 1001;
定点小数:反码

例如:
X = +0.1011,则 [X]原 = 0 1011;
X = -0.1011,则 [X]原 = 1 0100;
定点整数:补码
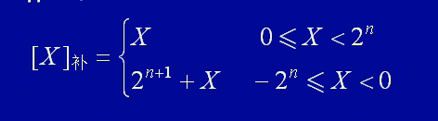
正数的补码与原码相同。负数的补码是该数的反码加1,这个加1就是“补”。
例如:
X = +0110,则 [X]原 = 0 0110;
X = -0110,则 [X]原 = 1 1010;
定点小数:补码
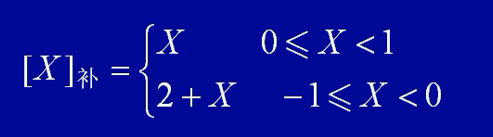
例如:
X = +0.1011,则 [X]原 = 0 1011;
X = -0.1011,则 [X]原 = 1 0101;
例:用定点补码表示纯小数,采用8位字长。编码1000 0000表示的十进制数是(-1)
[X]补 = 1000 0000,带入公式可求出为 -1 。
移码
求移码,只需要把补码的符号位进行取反即可得到。
例如:
X = +1011,[X]移= 1 1011,符号位1表示正号;
X = -1011,[X]移= 0 0101,符号位“0表示负号。
注意:移码只用于表示浮点数的阶码,所以只用于整数。
| 8位二进制原码的表示范围:-127~+127(有+0和-0) |
| 8位二进制反码的表示范围:-127~+127(有+0和-0) |
| 8位二进制补码的表示范围:-128~+127(只有一个0) |
校验码
循环校验码 CRC
模二除法


海明校验码
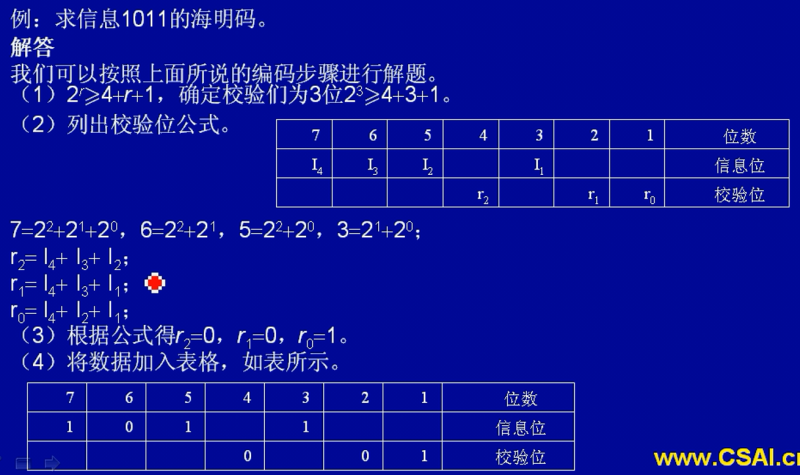
计算机的分类
Flynn 分类法
单指令流单数据流(SISD)
单指令流多数据流(SIMD)
多指令流单数据流(MISD)
多指令流多数据流(MIMD)

网络基础
网络的相关基础概念
网络的功能
- 数据通信
- 资源共享
- 负载均衡
- 高可靠性
网络的分类
广域网(LAN)
城域网(MAN)
局域网(LAN):以共享网络资源为目的,分布距离10米~1000米
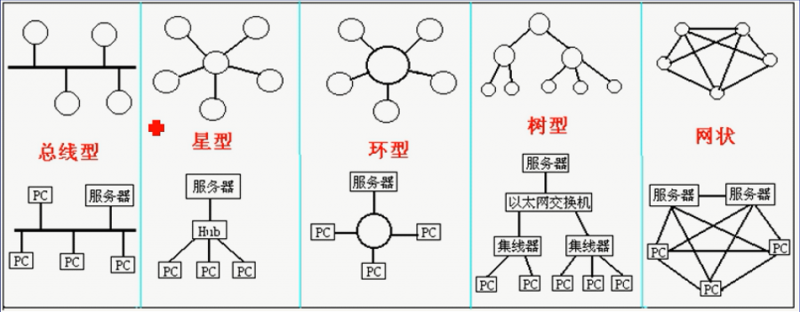
网络的拓扑结构
总线型拓扑结构:采用单根传输线作为公共的传输通道(CSMA/CD)
优点 :扩充性能好,可靠性高,廉价,安装方便
缺点:负载重时,线路的利用率低
树型拓扑结构:树根接受个站点发送的数据,然后再广播发送到全网
特性与总线型网路一样。
星型拓扑结构:以中央结点为中心与各结点连接而组成的
优点:维护方便,网络延迟时间短
缺点:线路利用率低,中央单元负荷重
环型拓扑结构:各结点通过环路接口连在一条首尾相连的闭合环形通路
优点:路径控制简单,可靠性高
缺点:扩充性差,传输效率低,响应速度慢
网状拓扑结构(分布式结构)
OSI 模型
- 应用层(直接和用户程序交互的一层)
- 表示层(对通信双方之间传输的数据做进一步的转换处理,以达到提高通信系统的通信效率和安全性等目的,如数据的加密/解密等)
- 会话层(会话的同步管理、会话的活动管理等)
- 传输层(提供无连接或面向连接的服务为基础,为双方的通信进程之间建立直接的端到端的数据传输通道)
- 网络层(路由,IP 地址)
- 数据链路层(把来自网络层的数据包按本层协议规定格式打包成数据帧,通过数据链路把帧从一个结点传输到相邻的某个结点)
- 物理层(实现通信双方之间的非结构化二进制比特流(物理服务数据单元)的传输)
通信子网:物理层、数据链路层、网络层
资源子网:会话层、表示层、应用层
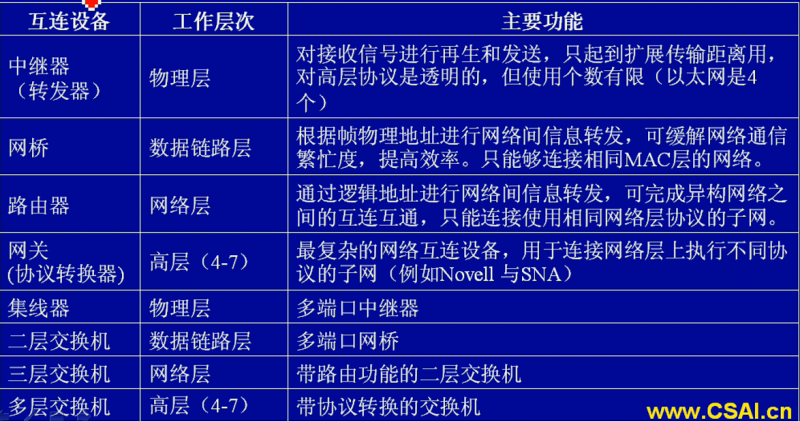
常见设备在 OSI 模型中所处层次:
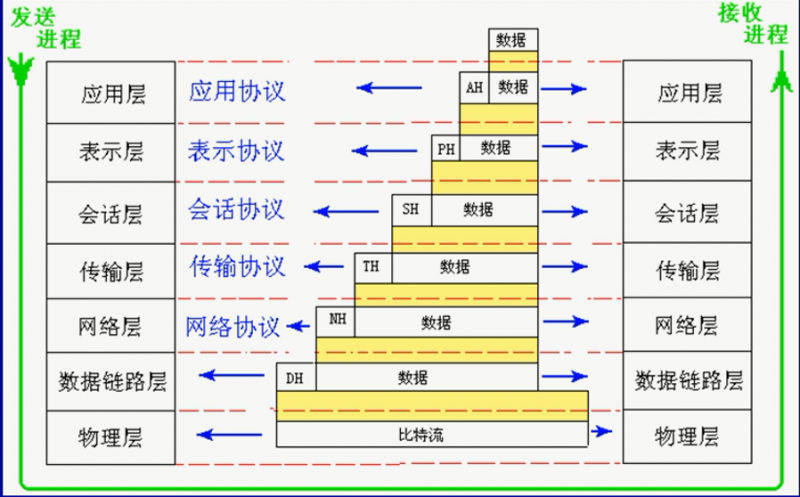
OSI 中的信息流向
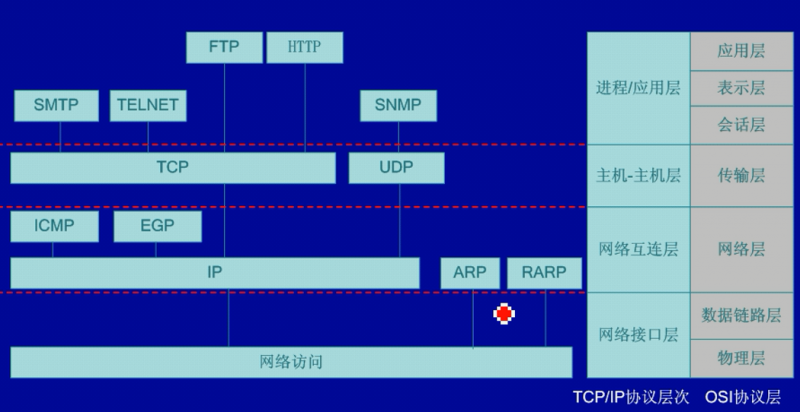
TCP/IP 协议族
- 应用层(各种应用层协议):为用户接口提供服务,如用于文件传输的FTP协议、HTTP协议、用于电子邮件的SMTP和POP3协议
- 传输层(TCP或UDP):TCP面向连接,可靠的传输服务。UDP相反。
- 网际层(IP):点到点的数据传输服务。数据传送的过程中能够选择合适的路由和结点。IP、ICMP、ARP和RARP等。
- 网络接口层

常用协议
ARP协议:将 IP 地址转成 MAC 地址。
常用端口知识
(1) 公共服务保留端口( Well known Ports):从0到1023
- 例如:
- 20是FTP的默认数据端口
- 21是FTP的默认控制口
- SMTP的默认端口是25
- 80端口是HTTP通讯端口
- POP3的默认端口是110
- 119 NNTP news新闻组传输协议
(2) 注册端口( Registered Ports):从1024到49151。
(3) 动态和或私有端口( Dynamic andlor Private Ports):从49152到65535。
ED|FAcT( EDI for Administration, Commerce and Transport)是多行业(行政、商业和运输)电子数据互换标准。
HDLc(High- evel Data Link Contro)是高级数据链路控制。

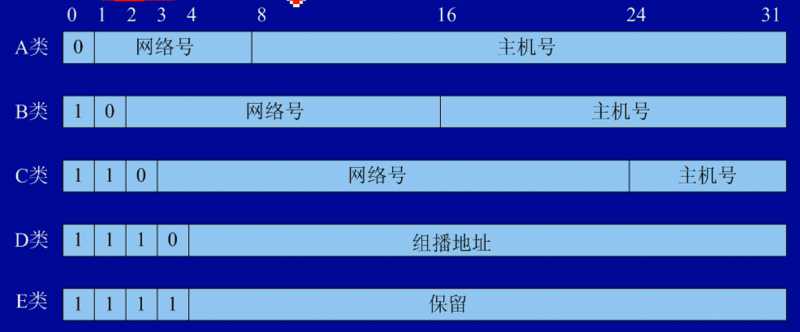
IP 地址的分类及子网的划分
IP 地址的分类
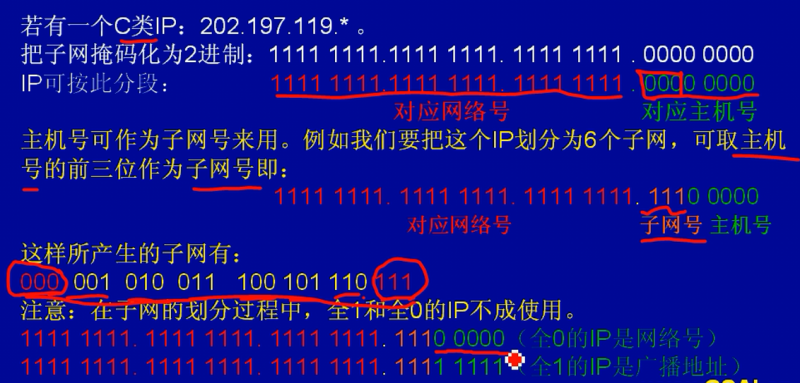
子网掩码的概念及子网划分
子网掩码的长度与形式都与|P地址一致
子网掩码的提出,是为了区分|P地址中的网络号和主机号。

子网的划分:
传输介质
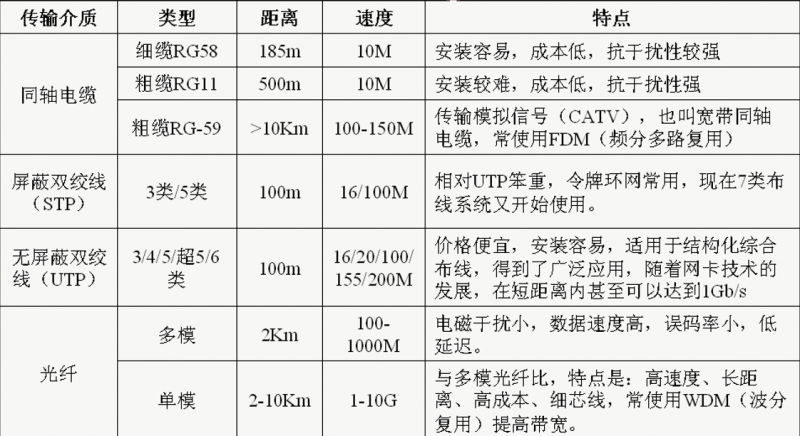
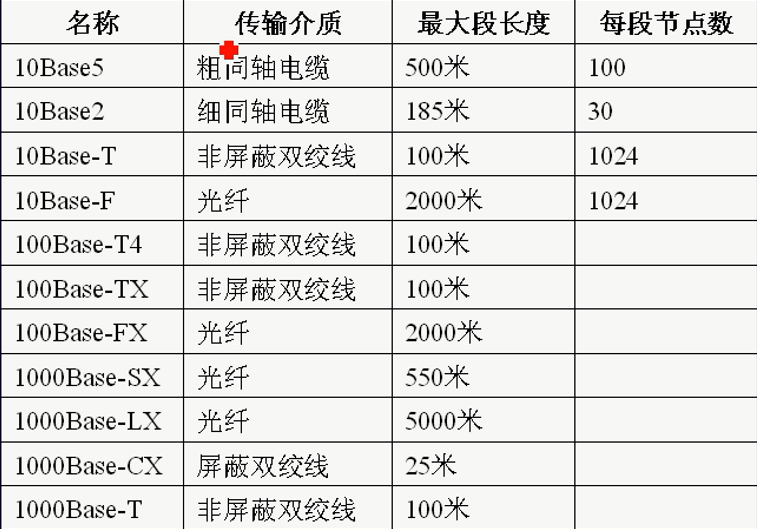
常用网络应用
WWW——万维网
在WWW中,依赖于标准化的统一资源定位器URL( uniformresource locator)地址来定位信息的内容。在进行页面访问时采用超文本传送协议HTTP(hypertexttransferprotocol),其服务端口就是HTTP服务端口(80端口)。首先,浏览器软件与HTTP端口建立一个TCP连接,然后发送GET命令,Web服务器根据命令取出文档,发送给浏览器;浏览器释放连接,显示文档。
E-Mail——电子邮件
电子邮件是现在数据量、使用量最大的一个互联网应用,它用来完成人际之间的消息通信。与它相关的有以下三个协议:
- SMTP:简单邮件传送协议,用于邮件的发送,工作在25号端口上
- POP3:邮局协议V3.0,用于接收邮件,工作在110号端口上
- IMAP:邮件访问协议,是用于替代POP3协议的新协议,工作在143号端口上。
DNS——域名解析协议
网络用户希望用有意义的名字来标识主机,而不是|P地址。为了解决这个需求,应运而生了一个域名服务系统DNS(工作在53号端口)。它是运行在TCP协议之上,负责将域名转换成实际相对应的P地址,从而在不改变底层协议的寻址方法的基础上,为使用者提供一个直接使用符号名来确定主机的平台。
DNS是一个分层命名系统,名字由若干个标号组成,标号之前用圆点分隔。最右边的是主域名,最左边的是主机名,中间的是子域名。例如:xinu.Cs. purdue. edu中,Ⅺnu是主机名、cs、 purdue是子域名(分别代表计算机系、普渡大学)、edu是主域名。可以看出一个域名可以由几个段组成,那么它们是怎样被赋值的呢?它是由国际域名管理机构lnη terNi来制。
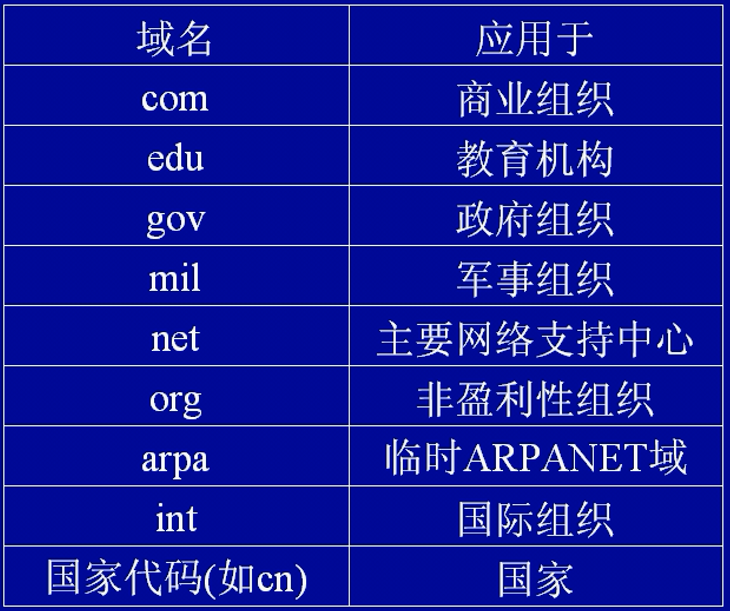
FTP——文件传输协议
FTP的传输模式包括:Bin(二进制)和AsC(文本文件)两种,除了文本文件之外,都应该使用二进制模式传输。
FTP应用的连接模式:在客户机和服务器之间需建立两条TCP连接,条是用于传送控制信息(21端口),一条则是用于传送文件内容(20端口)。
匿名FTP的用户名为 anonymous。
安全性、可靠性及系统性能评价
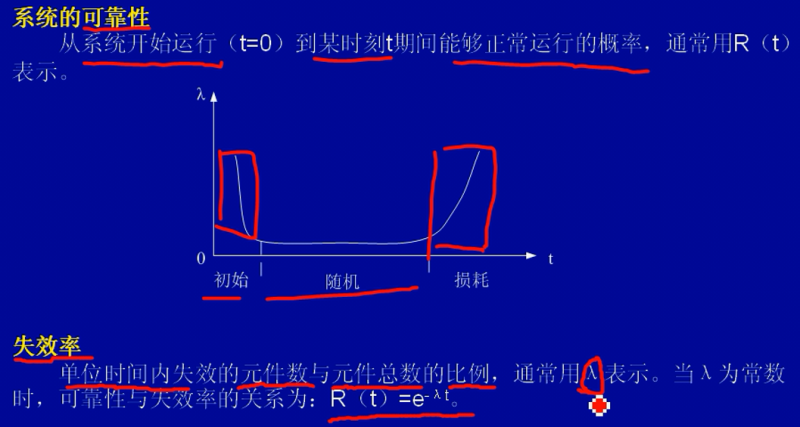
系统可靠性

数据安全与保密
对称加密技术
对此加密技术:是 指加密系统的加密密钥和解密密码相同。或者虽然不同,但从其中的任意一个可以很容易地推导出另一个。
常见对称密钥加密算法
DES(数据加密标准算法):DES主要采用替换和移位的方法加密。它用56位(64位密钥只有56位有效密钥)密钥对64位二进制数据块进行加密,每次加密可对64位的输入数据进行16轮编码,经一系列替换和移位后,输入的64位原始数据转换成完全不同的64位输出数据。
优点:加密速度快,密钥产生容易。
3DES(三重DES):在DES的基础上采用三重DES,即用两个56位的密钥K1、K2,发送方用K1加密,K2解密,再使用K1加密。接收方则使用K1解密,K2加密,再使用K1解密,其效果相当于将密钥长度加倍。
RC-5(Rivest cipher 5)RC5是由 Ron rivest(公钥算法的创始人之一)在1994年开发出来的。RC5是在RCF2040中定义的,RSA数据安全公司的很多产品都使用了RC-5。
IDEA算法:其明文和密文都是64位,密钥长度为128位。它比DES的加密性好,而且对计算机功能要求也没有那么高。DEA加密标准由PGP( PrettyGood Privacy)系统使用。
非对称加密技术
RSA 算法
信息摘要
信息摘要算法实际上就是一个单向散列函数。数据块经过单向散列函数得到一个固定长度的散列值,攻击者不可能通过散列值而编造数据块,使得编造的数据块的散列值和原数据块的散列值相同。
常用的消息摘要算法有MD5,SHA等,市场上广泛使用的MD5,SHA算法的散列值分别为 128 和 160 位,由于SHA通常采用的密钥长度较长,因此安全性高于MD5。
数字签名
在书面文件上签名是确认文件的一种手段,其作用有两点:
第一,因为自己的签名难以认,从而确认了文件已签署这一事实
第二,因为签名不易仿冒,从而确定了文件是真的这一手实。
数字时间戳技术
数字时间戳技术是数字签名一种变种的应用。
在电子商务交易文件中,时间是十分重要的信息。数字时间戳服务 Digital TimeStamp Service,DTS)是网上电子商务安全服务项目之一,能提供电子文件的日期和时间信息的安全保护。
时间戳( time-stamp)是一个经加密后形成的凭证文档,它包括3个部分:
1)需加时间戳的文件的摘要( digest)。
2)DTS收到文件的日期和时间。
3)DTS的数字签名。
SSL 安全协议
SSL安全协议最初是由 Netscape Communication公司设计开发的,又叫安全套接层( Secure Sockets Layer)协议”,主要用于提高应用程序之间数据的安圣系数。SSL协议的整个概念可以被总结为:一个保证任何安装了安全套接字的客户和服务器间事务安全的协议,它涉及所有TCP/P应用程序。
(1)SSL安全协议主要提供的服务
- 用户和服务器的合法性认证。
- 加密数据以隐藏被传送的数据。
- 保护数据的完整性。
(2)SSL安全协议实现的过程
- SSL安全协议是一个保证计算机通信安全的协议,对通信对话过程进行安全保护,其实现过程主要经过如下几个阶段。
- 接通阶段:客户机通过网络向服务器打招呼,服务器回应。
- 密码交换阶段:客户机与服务器之间交换双方认可的密码,一般选用RSA密码算法,也有的选用 Diffie- Hellmanηf和 Fortezza-KEA密码算法。
- 会谈密码阶段:客户机与服务器间产生彼此交谈的会谈密码
- 检验阶段:客户机检验服务器取得的密码。
- 客户认证阶段:服务器验证客户机的可信度。
- 结束阶段:客户机与服务器之间相互交换结束的信息。
网络安全
网络安全受到威胁的原因:
- 网络上存在秘密信息
- 网络系统存在缺阳
- 传输可控性差
- 网络协议存在不完善的地方
信息存储安全如何保障:
- 用户的标识与验证
- 用户存取权限控制
- 系统安全监控
- 计算机病毒防治
- 数据加密
信息传输加密:
- 链路加密
- 节点加密
- 端-端加密
VPN 技术
防火墙
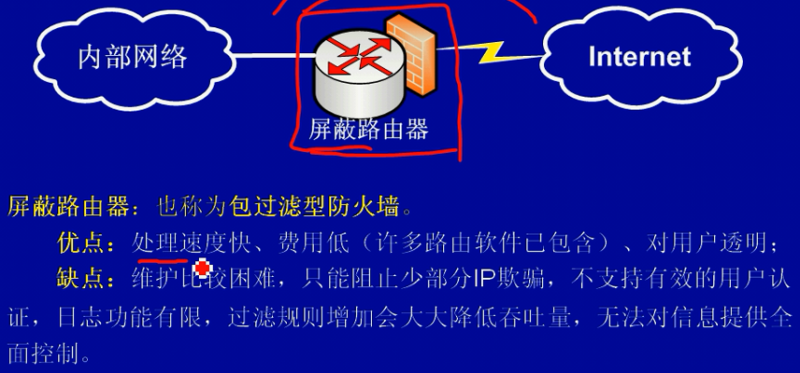
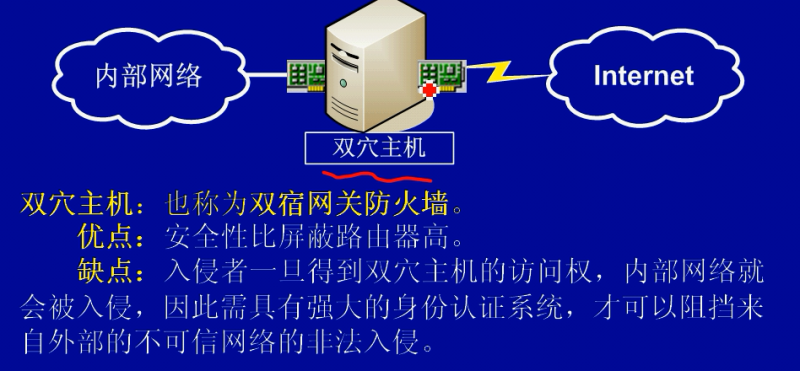
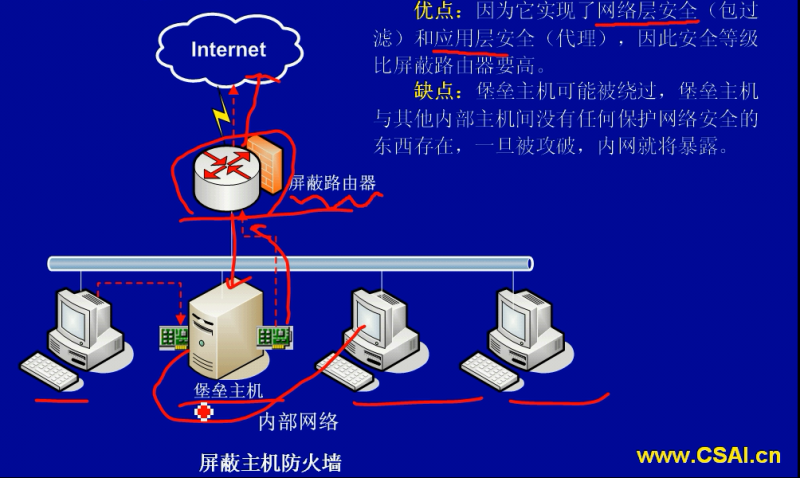
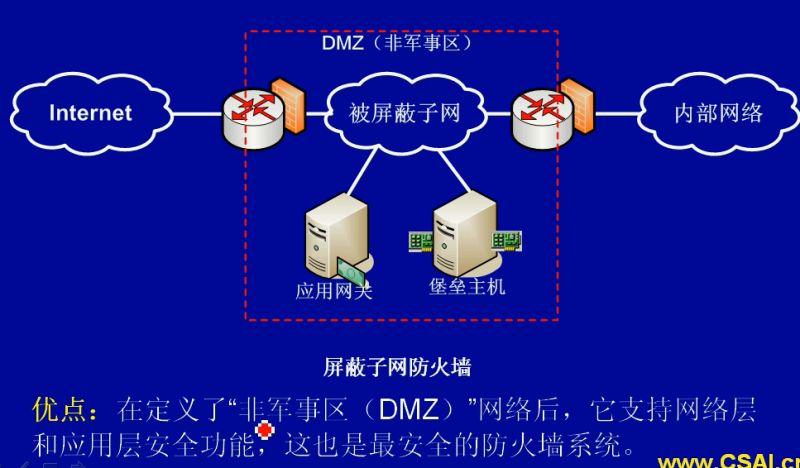
类型:
- 包过滤防火墙(应用于网络层,无法防范黑客的攻击)
- 应用代理网关防火墙
- 状态检测技术防火墙
标准化
基本概念
标准:对重复性的事务和概念所做的统一规定。以科学、技术和实践经验的综合成果为基础,经有关方面协商一致,由一个公认机构批准,以特定形式发布,作为共同遵守的准则和依据。
标准化:是指在经济、技术、科学及管理等社会实践中,对重复性事物的概念通过制订、发布和实施标准达到统一,以获得最佳秩序和社会效益的活动。它是一门综合性学科,具有综合性、政策性和统一性的特点。
标准化的过程:一般包括标准产生(调查、研究、形成草案、批准发布)、标准实施(宣传、普及、监督、咨询)和标准更新(复审、废止或修订)三个子过程。
标准化的实质和目的是什么?
- 通过制定、发布和实施标准,达到统 是标准化的实质。
- 获得最佳秩序和社会效益 则是标准化的目的。
标准化的对象是什么?
- 在国民经济的各个领域中,凡具有多次重复使用和需要制定标准的具体产品,以及各种定额、规划、要求、方法、概念等,都可称为标准化对象。
标准化对象一般可分为两大类:
- 一类是标准化的具体对象,即需要制定标准的具体事物;
- 另一类是标准化总体对象,即各种具体对象的总和所构成的整体,
制定标准的原则是什么?
制定标准应遵循的原则是:
- 要从全局利益出发,认真贯彻国家技术经济政策;
- 充分满足使用要求
- 有利于促进科学技术发展
制定标准要经过哪几个阶段?
一项标准的出台一般要经过六个阶段:
- 第一阶段,申请阶段;
- 第四阶段,审査阶段
- 第二阶段,预备阶段;
- 第五阶段,批准阶段;
- 第三阶段,委员会阶段;
- 第六阶段,发布阶段
标准的更新
1.标准复审
根据我国《国家标准管理办法》的规定:国家标准实施后,应当根据科学技术的发展和经济建设的需要,由该国家标准的主管部门组织有关单位适时进行复审,复审周期一般不超过五年。
2.标准确认
只在标准再版时在标准封面写明*年确认的字样即可。
3.标准修订
修订后的标准,标准号不变,年号更新为修订版发布时的年份。
标准的编号
国际、国外标准代号及编号:标准代号+专业类号+顺序号+年代号。
我国标准代号及编号:
- 强制性国家标准代号为GB
- 推荐性国家标准代号为GBT
- 行业标准代号由汉语拼音大写字母组成(如航天QJ,电子SJ,机械JB、金融JR)
- 地方标准代号由大写汉语拼音DB加上省级行政区划代码的前两位。
- 企业标准代号由“Q加上企业代号组成。
常见标准化组织
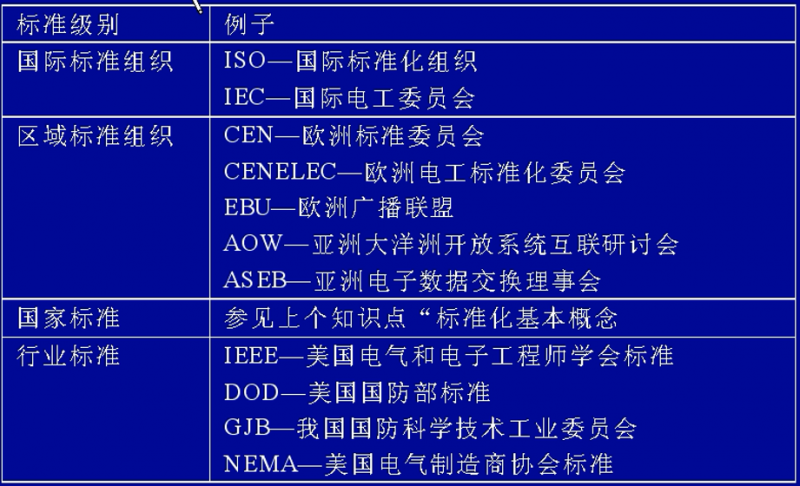
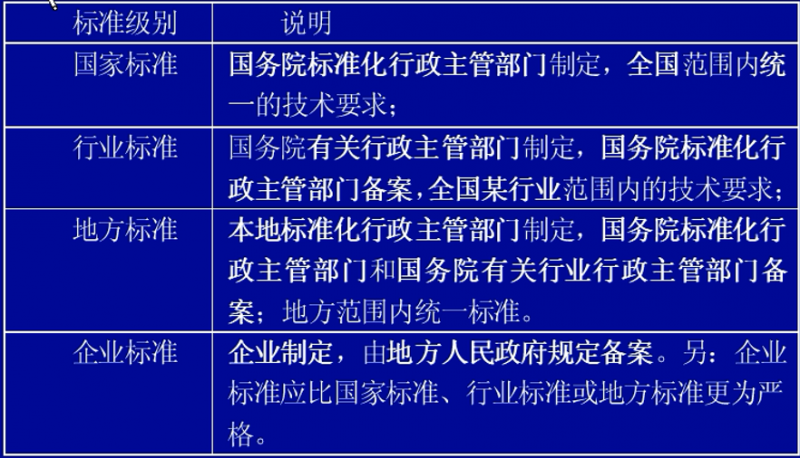
我国的标准分类
面向对象技术
基本概念
对象:对象( object)是系统中用来描述客观事物的一个实体,它是构成系统的个基本单位。
对象三要素:对象标识、属性和方法。
封装( encapsulation)是对象的一个重要原则。
它有两层含义:
- 第一,对象是其全部属性和全部服务紧密结合而形成的一个不可分割的整体
- 第二,对象是一个不透明的黑盒子,表示对象状态的数据和实现操作的代码都被封装在黑盒子里面。
类:对具有相同属性和服务的一个或一组对象的抽象。类与对象是抽象描述和具体实例的关系,一个具体的对象被称作类的一个实例。类属是一种参数多态机制。
继承与泛化:继承是面向对象方法中重要的概念,用来说明特殊类(子类),与一般类(父类)的关系,通常使用泛化来说明一般类与特殊类之间的关系它们之间是一对多关系。
多态性与重载:多态(即多种形式)性则是指一般类中定义的属性或服务被特殊类继承后,可以具有不同的数据类型或表现出不同的行为,通常是使用重载和改写两项技术来实现的。
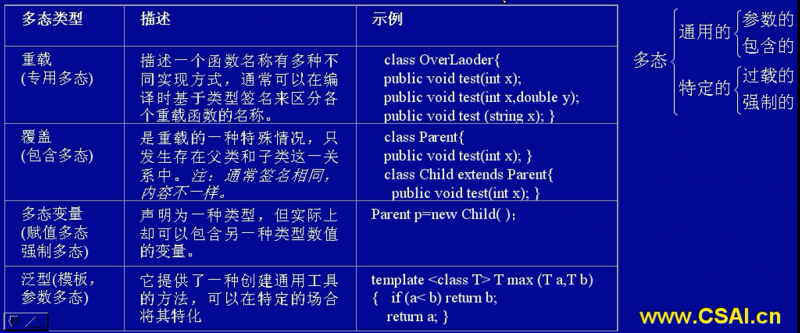
消息和消息通信:消息就是向对象发出的服务请求,它通常包括提供服务的对象标识、消息名、输入信息和回答信息。消息通信则是面向对象方法学中的个重要原则,它与对象的封装原则密不可分,为对象间提供了惟一合法的动态联系的途径。
面向对象方法学的优点:
- 与人类习惯的思维方法一致
- 稳定性好
- 可重用性好
- 较易开发大型软件产品
- 可维护性好
OOA/OOD
OOA 模型由5个层次和五个活动组成。
五个层次分别是:主题、对象类、结构、属性和服务。
五个活动是标识对象类、标识结构与关联、划分主题、定义属性、定义服务。
此外,在 OOA 中还定义了两种对象类之间的结构:分类结构和组装结构。
OOD
它由人机交互部件、问题域部件、任务管理部件、数据管理部件四个部分组成,其主要的活动就是这四个部件的设计工作。
Booch方法
Booch认为软件开发是一个螺旋上升的过程。在这个螺旋上升的每个周期中,有以下几个步骤
发现类和对象
确定它们的含义
找出它们之间的相互关系
说明每一个类和对象的界面和实现
| 静态模型 | 动态模型 | |
|---|---|---|
| 逻辑模型 | 类图、对象图 | 状态装换图、时序图 |
| 物理模型 | 模块图、进程图 |
OMT方法
OMT 定义了三种模型:对象模型、动态模型和功能模型。

进行 OMT 建模时的四个活动:分析、系统设计、对象设计和实现。
面向对象程序设计
this 指针的使用

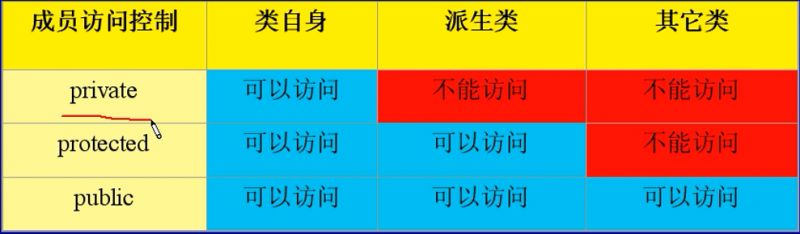
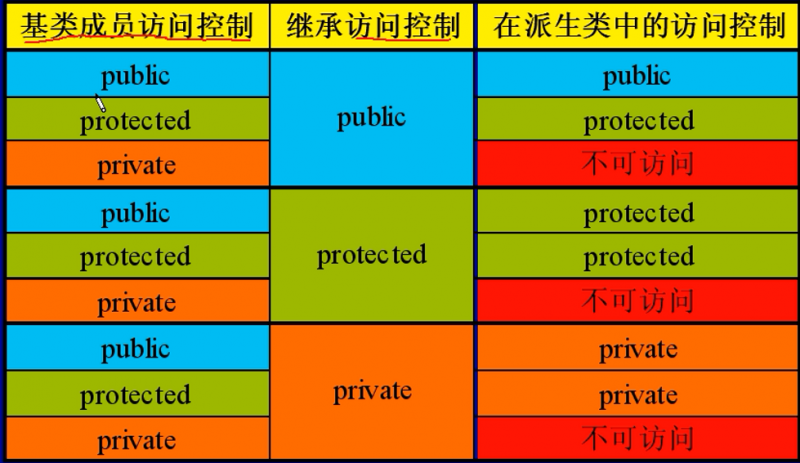
继承成员访问控制机制
设计模式
设计模式的要素
- 模式名称
- 问题
- 解决方案
- 效果
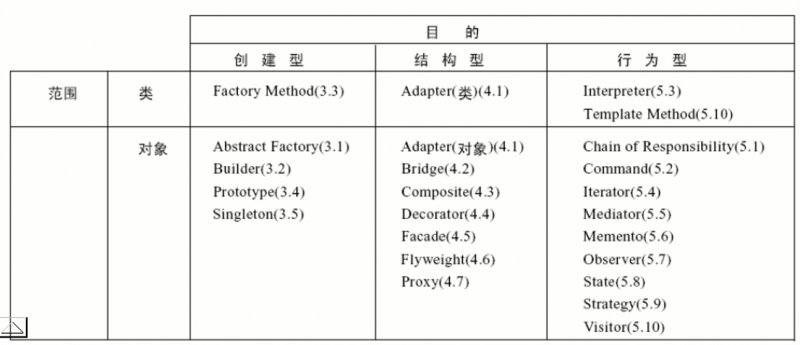
设计模式的分类
模式分类的两条原则:
- 目的(创建型、结构型、行为型)
- 范围(类、对象)
怎样使用设计模式?
- 大致浏览一遍模式
- 回头研究结构部分、参与者部分和协作部分
- 看代码示例部分,看看这个模式代码形式的具体例子
- 选择模式参与者的名字,使它们在应用上下文中有意义
- 定义类
- 定义模式中专用于应用的操作名称
- 实现执行模式中责任和协作的操作
模式设计中用到的几个重要思想理念
- 对接口编程,而不对实现编程
- 对类的功能的扩展,要多用组合,少用继承
对类的功能的扩展,要多用组合,少用继承。
原因:
- 子类对父类的继承是全部的公有和受保护的继承,这使得子类可能继承了对子类无用甚至有害的父类的方法。换句话说,子类只希望继承父类的一部分方法,怎么办?
- 实际的对象千变万化,如果每一类的对象都有他们自己的类,尽管这些类都继承了他们的父类,但有些时候还是会造成类的无限膨胀。
- 继承的子类,实际上需要编译期确定下来,这满足不了需要在运行内才能确定对象的情况。而组合却可以比继承灵活得多,可以在运行期才决定某个对象。
创建型模式
结构型模式
行为型模式
知识产权
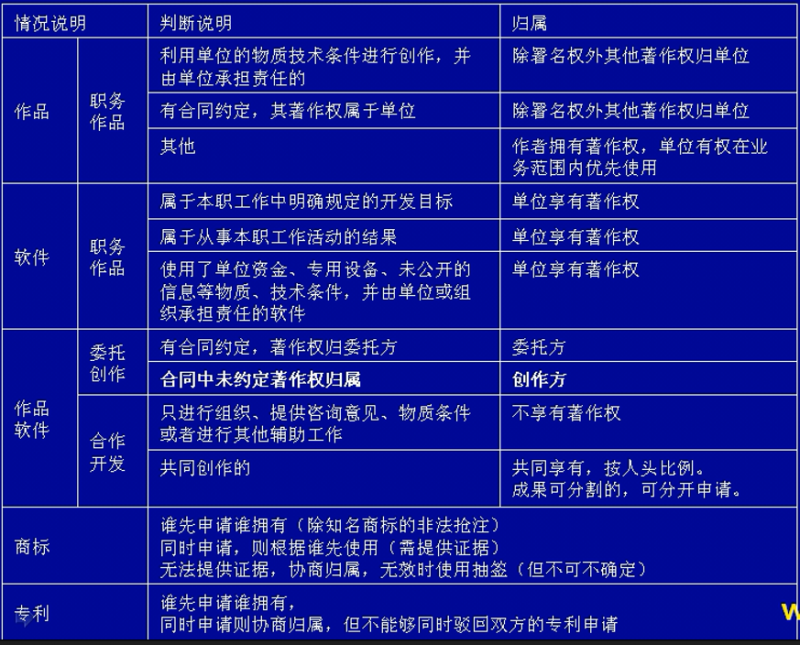
以下形为都为侵权行为:
- 未经著作权人许可,发表其作品的
- 未经合作作者许可,将与他人合作创作的作品当作自己单独创作的作品发表的;
- 没有参加创作,为谋取个人名利,在他人作品上署名的;
- 歪曲、篡改他人作品的;
- 剽窃他人作品的;
- 未经著作权人许可,以展览、摄制电影和以类似摄制电影的方法使用作品,或者以改编、翻译、注释等方式使用作品的,本法另有规定的除外;
- 使用他人作品,应当支付报酬而未支付的;
- 未经电影作品和以类似摄制电影的方法创作的作品、计算机软件、录音录像制品的著作权人或者与著作权有关的校利人许可,出租其作品或者录音录像制品的,本法另有规定的除外
- 未经出版者许可,使用其出版的图书、期刊的版式设计的;
- 未经表演者许可,从现场直播或者公开传送其现场表演,或者录制其表演的;
- 其他侵犯著作权以及与著作权有关的权益的行为。
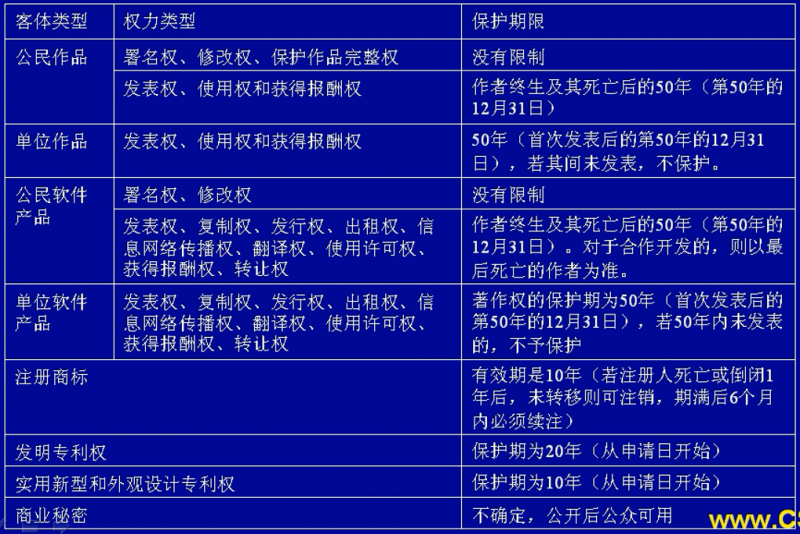
软件著作权自软件开发完成之日起产生
自然人的软件著作权,保护期为自然人终生及其死亡后50年,截止于自然人死亡后第50年的12月31日;软件是合作开发的,截止于最后死亡的自然人死亡后第50年的12月31日。
法人或者其他组织的软件著作权,保护期为50年,截止于软件首次发表后第50年的12月31日,但软件自开发完成之日起50年内未发表的,本条例不再保护。
有下列侵权行为的,应当根据情况,承担停止侵害、消除影响、赔礼道歉、赔偿损失等民事责任:
- 未经软件著作权人许可,发表或者登记其软件的;
- 将他人软件作为自己的软件发表或者登记的
- 未经合作者许可,将与他人合作开发的软件作为自己单独完成的软件发表或者登记的
- 在他人软件上署名或者更改他人软件上的署名的;
- 未经软件著作权人许可,修改、翻译其软件的;
- 其他侵犯软件著作权的行为
商标法第十九条
两个或者两个以上的申请人,在同一种商品或者类似商品上,分别以相同或者近似的商标在同一天申请注册的,各申请人应当自收到商标局通知日起30日内提交具甲请注卅前在先使用该商标的证据。同日使用或者均未使用的,各申请人可以自收到商标局通知之日起30日内自行协商,并将书面协说报送商标局;不愿协商或者协商不成的,商标局通知各申请人以抽签的方式确定一个申请人,驳回其他人的注册申请。商标局已经通知但申请人未参加抽签的,视为放弃申请,商标局应当书面通知未参加抽签的申请人。
商标法第三十七条
注册商标的有效期为十年,自核准注册之日起计算。
多媒体
媒体的分类
- 感觉媒体
- 表示媒体(图像编码、文本编码、声音编码等)
- 表现媒体(键盘、鼠标、扫描仪、显示器等)
- 交换媒体(存储媒体和传输媒体)
多媒体的特征
- 多样性
- 集成性
- 交互性
- 非线性
- 实时性
- 信息使用的方便性
- 信息结构的动态性
虚拟现实技术
概念
虚拟现实是将现实世界的多维信息映射到计算机的数字空间生成相应的虚拟世界。
分类
- 桌面虚拟现实
- 完全沉浸的虚拟现实
- 增强现实性的虚拟现实
- 分布式虚拟现实
声音
声音信号的两个基本参数是幅度和频率。幅度是指声波的振幅,通常用声压级表示,计量单位是分贝(dB)。频率是指声波每秒钟变化的次数,用 Hz 表示。
人耳能听到的声音信号的频率范围是20Hz~20kHz。小于20Hz的声波信号称为亚音信号(次声波)。大于20kHz的声波信号称为超音频信号(超声波)。
声音文件格式
- .wav
- .snd
- .au
- .aif
- .voc
- .mp3
- .ra
- .mid、.rmi
颜色
颜色的三要素
- 色调。指颜色的类别。
- 饱和度。指某一颜色的深浅程度(或浓度)。
- 亮度。描述光作用于人眼时引起的明暗程度感觉,是指彩色明暗深浅程度。
三基色
红色、绿色、蓝色
颜色模型
- RGB颜色模型,自发光的彩色显示器。
- CMY颜色模型(青色、品红色、黄色),打印机。
- YUV颜色模型。
图形和图像
概念
图形。由矢量表示的图形是用一系列计算机指令来描述和记录的一幅图的内容。编辑矢量图的软件通常称为绘图软件。
图像。图像是指用像素点来描述的图。(二值图像、灰度图像、彩色图像)
图像的属性
分辨率
分为图像分辨率和现实分辨率
图像分辨率大于显示分辨率时,在屏幕上只能显示部分图像;图像分辨率小于希纳是分辨率时,图像只占屏幕的一部分。
例如:用200dpi来扫描一幅2x2.5英寸的彩色照片,可以得到一幅400x500个像素点的图像。
像素深度
像素深度是指存储每个像素所用的二进制位数,它也是用来度量图像的色彩分辨率的。
例如:像素的深度为10位,每个像素可以是2^10中颜色中的一种。表示一个像素的位数越多,它能表达的颜色数目就越多,它的深度也就越深。
真彩色和伪彩色
真彩色是指组成一幅彩色图像的每个像素值中由R、G、B3个基色分量,每个基色分量直接决定显示设备的基色强度。例如,R、G、B分量都用8位来表示,可生成的颜色数,就是2^24种。图像的压缩
图像的压缩编码
计算数据量公式:
图像数据量 = 图像的总像素数 x 像素深度 / 8(Byte)
例如,一幅640x480的256色图像,其数据量为:640x480X8/8 = 300KB
图像文件格式
- .bmp
- .gif
- .tif
- .pcx
- .png
- .jpg(JPEG)
- .wmf
数据流图设计
百度资源
链接: https://pan.baidu.com/s/1zPJIWeo6_WBJCfsGdd5GhA 提取码: fgm2


